


Nvidia has unveiled a RAG-based Retriever service to stop generative AI hallucinating inaccurate responses.
The NeMo Retriever is a generative AI microservice that enables enterprises to connect custom large language models to enterprise data, thereby delivering accurate responses to an AI application user’s requests and questions. It essentially involves semantic retrieval, with retrieval-augmented generation (RAG) capabilities that utilize Nvidia algorithms. It is part of Nvidia’s AI Enterprise software platform and is available in the AWS Marketplace.
Jensen Huang, Nvidia co-founder and CEO, stated: “Generative AI applications with RAG capabilities are the next killer app of the enterprise. With Nvidia NeMo Retriever, developers can create customized generative AI chatbots, copilots and summarization tools that can access their business data to transform productivity with accurate and valuable generative AI intelligence.”
NeMo Retriever supports production-ready generative AI with commercially viable models, API stability, security patches, and enterprise support, unlike open source RAG toolkits. It contains embedding models that capture relationships between words, enabling LLMs (large language models, the technology underlying generative AI) to process and analyze textual data.
Nvidia claims that enterprises can connect their LLMs to multiple data sources – such as text, PDFs, images, videos, and knowledge bases – so that users can interact with data and receive accurate, up-to-date answers using simple, conversational prompts.
It asserts that enterprises can use NeMo Retriever to achieve more accurate results with less training, speeding up time to market and supporting energy efficiency in the development of generative AI applications.
Cadence (industrial electronics design), Dropbox, SAP, and ServiceNow are collaborating with Nvidia to integrate production-ready RAG capabilities into their custom generative AI applications and services.
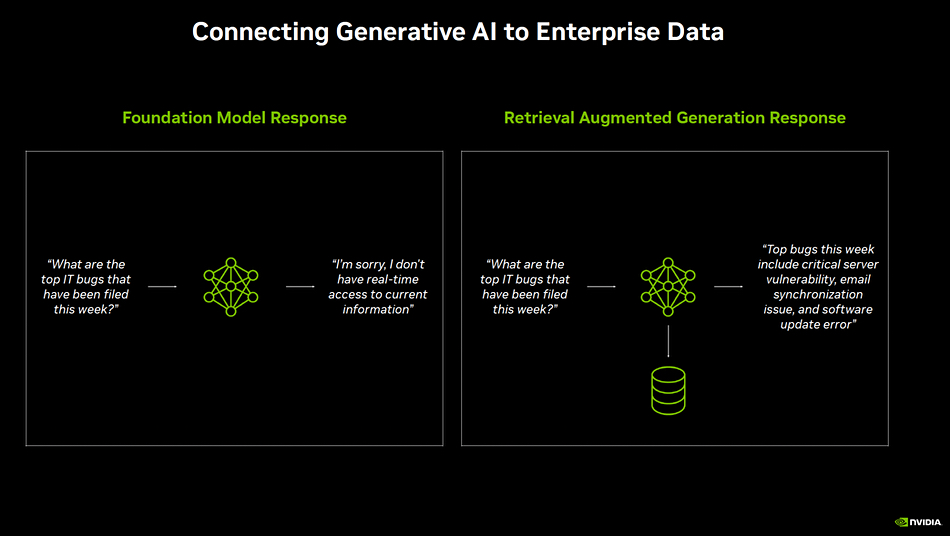
Preventing LLM hallucinations
Retrieval-augmented generation is a way of minimizing hallucinatory generative AI chatbot LLM responses from underlying LLMs trained on a general trove of information rather than domain-specific data. It works by turning a user’s request into a set of coded parameters called vector embeddings. These are then used to query a domain-specific database of information local or specific to the user’s organization. This database contains vector embeddings of data relevant to the organization and the RAG query looks for similarities between the input request vector embeddings and the database’s vector embedded content, choosing the content with the closest similarity.
Minimising hallucination isn’t the same as eliminating it, though. The RAG process requires verification to ensure the output is contextually relevant, grounded, and accurate. Vectara has developed an open source Hallucination Evaluation Model to assist in this verification.




