


MinIO doubled down on its open source, Kubernetes-native object storage at an IT Press Tour briefing.
The company said its object storage software was frequently downloaded (1.2 billion Docker pulls) and widely deployed. Its thesis starts with the point that the cloud is taking over virtually every IT environment. Kubernetes powers the cloud operating model, providing one abstraction across any computing infrastructure – public, private or edge.
CMO Jonathan Symonds claimed: “We are the world’s fastest object store and no one has challenged us.”
He justifies the claim by citing GET speeds of 325GiBps and PUT speeds of 177 GiBps on standard hardware.
The primary storage format or protocol in Kubernetes environments is object, not block or file. The cloud runs on RESTful APIs. POSIX is legacy at this point as are the storage classes that depend on it.
MinIO says properly architected systems offer performance at scale – a requirement for AI/ML workloads. MinIO object storage is built for this, with erasure coding and S3 Select support. It asserts that, despite decades of evolution, file and block storage, lacking these things is not good enough for modern cloud environments.
Symonds said: “We don’t see SAN and NAS as being natural in the cloud world.”
In a nutshell, its position is that EC2 and file in the cloud cannot scale as easily as object. iSCSI as a service and TCP are both too chatty for cloud, it claims, and NFS v4 and pNFS don’t scale. S3 came much later, dropped the legacy baggage, and became primary. RAID doesn’t scale, MinIO feels.
Basically, MinIO is convinced its object software will wash over everything else in the storage world, including on-premises file, block and object arrays, and their semi-detached, CSI-based cloud incarnations. Why? Because it is fast and Kubernetes-native, and therefore suited for storage provision in the cloud.
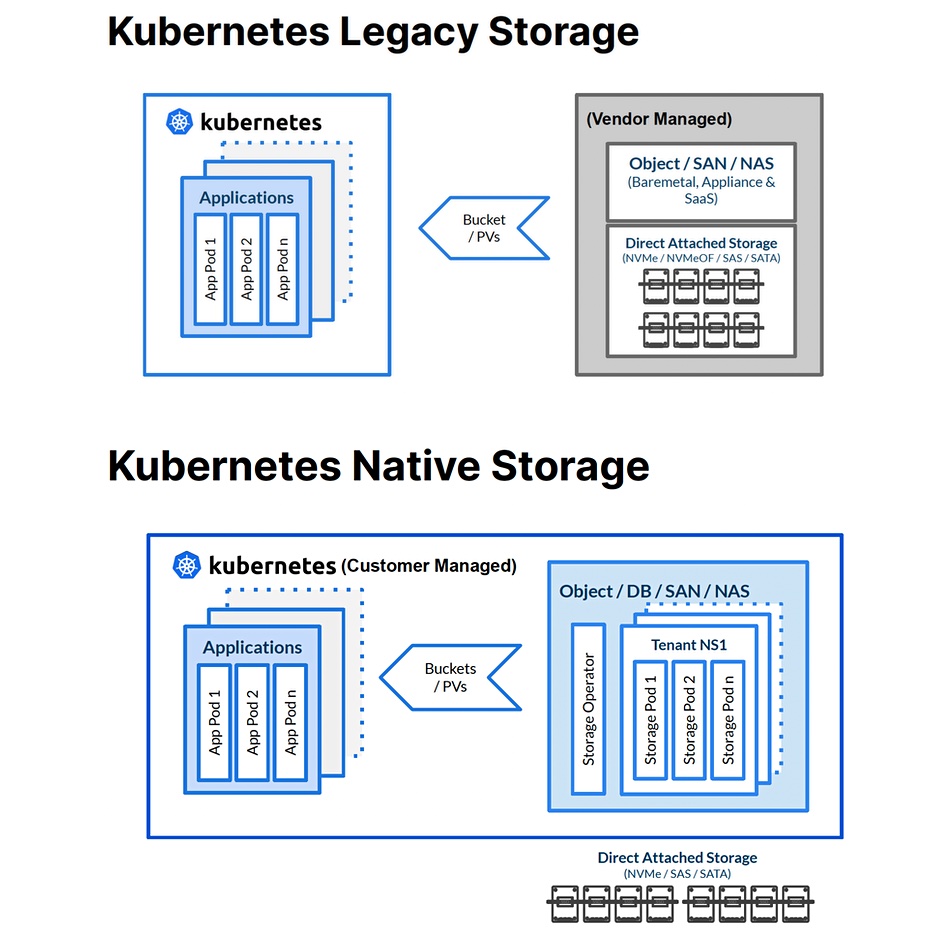
Being Kubernetes-native matters because the entire storage software runs as a container inside of Kubernetes, with complete support for all Kubernetes functionality, it says.
Symonds said file and block are in the cloud for legacy apps, and file and block have to go through the kernel and so have CSI drivers. MinIO’s object store runs as a container and doesn’t need CSI.
MinIO claims S3 is the default API for object storage and MinIO is the leader in compatibility. It claims to have been the first to market with V4 and one of the few to support S3 Select.
Its operator provisions multiple MinIO clusters on top of Kubernetes. It brings stateful services to the world of Kubernetes, which doesn’t understand the concept of state, and makes having multiple tenants with multiple versions straightforward. Operators enable seamless integration with the broader K8s ecosystem, giving access to service discovery, container orchestration, and monitoring systems.
The operator works with Amazon EKS, AKS, GKE, OpenShift, RAFAY, the Rancher Kubernetes Engine and VMware Tanzu. V5.0 brings in zero trust. It’s workload-centric and workload identity can be validated by MinIO Operator with help of K8s. V5 has rotating credentials control. All access granted to object store is temporary and there is no need to worry about rotating credentials ending up with the wrong user/workload.
There is dynamic local persistent volume (PV) provisioning as opposed to network PV provisioning.
Scale
MinIO engineer Dileeshvar Radhakrishnan said unstructured data will represent 90 percent of all of data by 2025. MinIO storage can be used as a data lake and is suited to storing data for AI/ML processing. AI predominantly uses object storage and MinIO said it was ready for any ChatGPT-led acceleration.
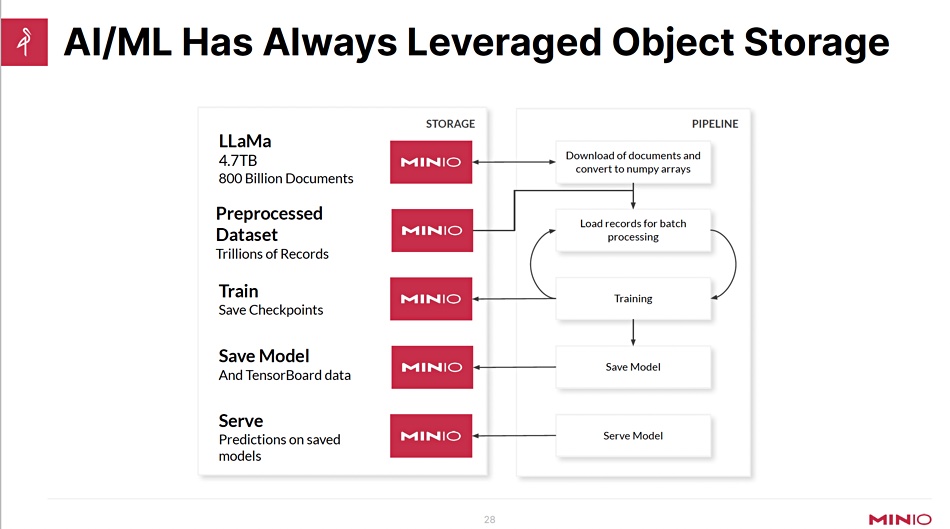
The petabyte is the new terabyte, as it were, and we are moving into exabyte territory. Data lakes use object storage, not SAN, NAS or block storage, because they don’t scale.
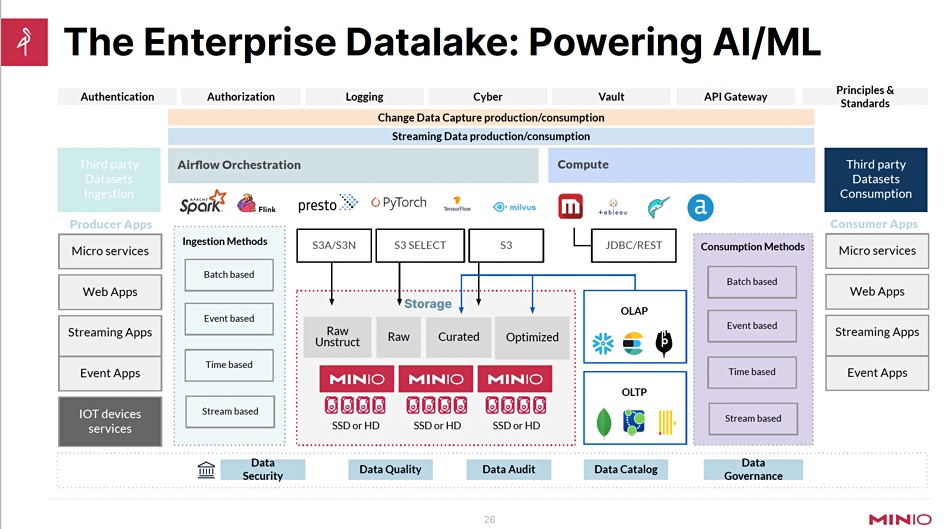
But PB/EB-scale data is often distributed and must be seen as a single element instead of being viewed as siloed. Public cloud economics don’t work at EB scale; it is simply too costly. Data has to be on-premises or in a colo, and stored with MinIO software. This uses Kafka. It has an Iceberg driver which takes data and stores it in MinIO ISO tables.
In Radhakrishnan’s view: “Basically we are the poster child for the modern data lake.”
We asked the MinIO presenters about about enterprise customers of VAST Data, Pure Storage, etc. with commitment to Nvidia and its GPUDirect protocol. MinIO, which doesn’t support GPUDirect, thinks these customers have made the wrong choice, but they won’t listen to MinIO.
It will leave these customers of legacy vendors like Dell, NetApp, Pure, VAST, etc, on their own. They will stay with their choices and MinIO will not address them. Instead it will let this smaller SAN/NAS market wither away over time, while it grows in the the much larger object market. This will consolidate, with Kubernetes acting as the convergence point.
Defending open source
MinIO has been vocal in acting against suppliers such as Nutanix and Weka.
Symonds said: ”We are deeply committed to open source.”
He said this about the actions against Nutanix and Weka: “We see this as defending open source.” MinIO wants them to play by the open source rule book, meaning its licensing rules.
Bootnote
Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop. They are clients of the Kubernetes API that act as controllers for a custom resource.





