


Dremio’s latest data lake analytics release provides more than five times faster SQL expression processing than its June version.
Dremio supplies in-memory software, powered by Apache Arrow, to analyse data stores using SQL. Its Dart initiative aims to make it possible to run SQL workloads directly on source data lakes instead of on data warehouses fed by extract, transform and load procedures. It has been pumping out software updates to help achieve this.
Tomer Shiran, founder and Chief Product Officer at Dremio, said: “We want to push the boundaries of what’s possible in the data lakehouse and deliver the best [business intelligence] experience for our customers. To that end, the Dart Initiative has been chipping away at the Zone of Confusion between data lakes and warehouses in critical areas such as query performance and acceleration, SQL coverage, and transactionality.”
The “Zone of Confusion” is a Gartner expression referring to the overlap in analytics processing of data lakes and warehouses. We might say Shiran’s data lakehouse idea adds verbal confusion. The point of running ETL procedures is get more structured data into a data warehouse so that analytic routines can deliver results faster.
This latest software release provides near real-time metadata refresh for datasets by refactoring metadata processing to become a parallel, executor-based process, with metadata stored and managed in Apache Iceberg tables. This delivers metadata refresh times up to 20x faster than previous versions and performance improves as the dataset size increases. This graph illustrates the point:
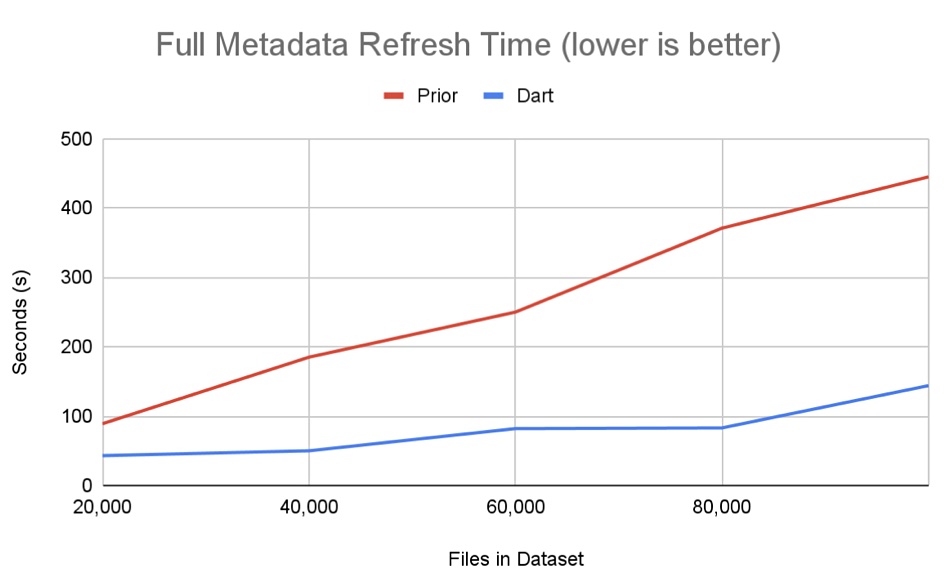
The company says Arrow component Gandiva is an LLVM-based toolkit that enables vectorised execution directly on in-memory Arrow buffers, by generating code to evaluate SQL expressions that fully leverage the pipelining and SIMD capabilities of modern CPUs. This latest Dart Initiative release enables Dremio to accelerate expression processing rates by over 5x, and in some cases by 30x, as another chart indicates:
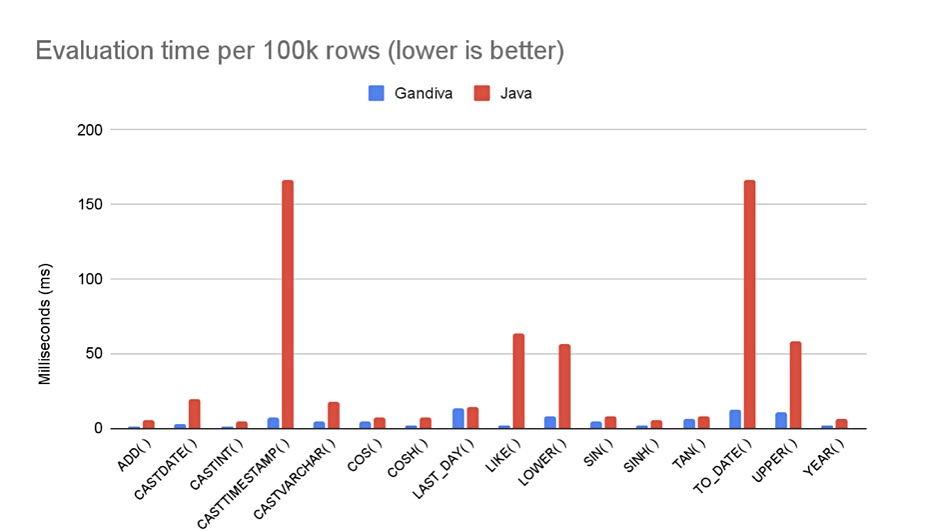
The latest release adds Pivot/Unpivot and filtered aggregates functions. Dremio says risk analysis in insurance, maximising revenue in travel and transportation, improving clinical trials in pharma, and enabling credit risk assessment in banking are among the use cases that can benefit from this.





