


IBM has launched the Elastic Storage System (ESS) 5000 and updated Cloud Object Storage (COS) and Spectrum Discover as part of a new AI storage portfolio.
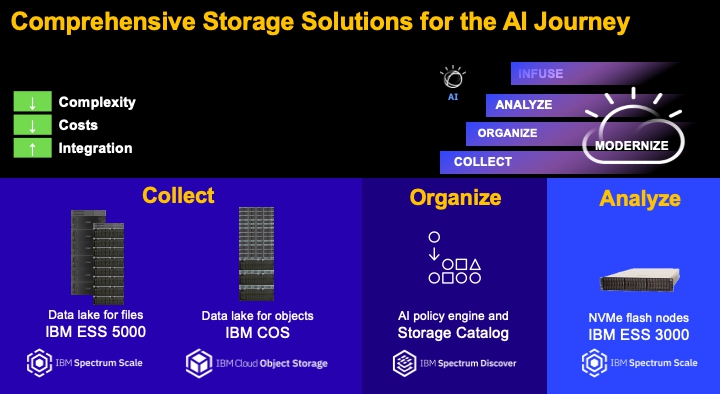
The company laid out its vision for an AI pipeline in a webcast with Eric Herzog, chief marketing officer at IBM Storage, and Sam Werner, VP of Storage Offering Management. This vision comprises a pipeline with Collect, Organise and Analyse stages, with IBM offerings tailored for each stage.
According to Werner, 80 per cent of firms expect AI use cases to increase within the next two years, yet at the same time 89 per cent of them say deploying AI is a struggle, largely because of data challenges. So, an information architecture for AI is required, and this is where IBM is aiming its new and updated portfolio.
The new ESS 5000 is optimised for the Collect stage. This is based around IBM Power9 servers and operates the firm’s Spectrum Scale parallel file system. IBM claims it is capable of 55GB/sec from a single eight-disk enclosure, and can scale up to handle an impressive eight yottabyes of capacity in its role as a data lake. IBM said this compares favourably against competing products such as NetApp FAS and Dell EMC’s Isilon line.

Two configurations are on offer: the SL model fits in a standard rack and scales-up to 8.8PB with six enclosures, while the SC fits in an extended rack and scales-up to 13.5PB with eight enclosures. The ESS 5000 is set for general availability from August.

Also fitting into the Collect stage is IBM COS, which is designed to run on commodity x86 servers. This has undergone a complete revamp of its storage engine, designed to increase system performance to 55 GB/sec in a 12-node configuration. This can improve read performance by 300 per cent and writes by 150 per cent depending on object size, according to IBM.
COS will soon support host-managed shingled magnetic recording (SMR) drives for improved density, delivering up to 1.9 PB in a 4U disk enclosure with 18TB SMR disks. This update will be available from August.
For the Analyse part of the pipeline, IBM’s solution is the ESS 3000. This all-flash NVMe system in a 2U enclosure was launched last October and also runs Spectrum Scale with a performance of 40GB/sec.
IBM said that although the ESS 3000 or the ESS 5000 are both Elastic Storage with Spectrum Scale file systems and could thus be put to work in any part of the AI pipeline, it is positioning the ESS 3000 as best for Analyse and the ESS 5000 as best for Collect, owing to the lower cost per GB the latter system offers.
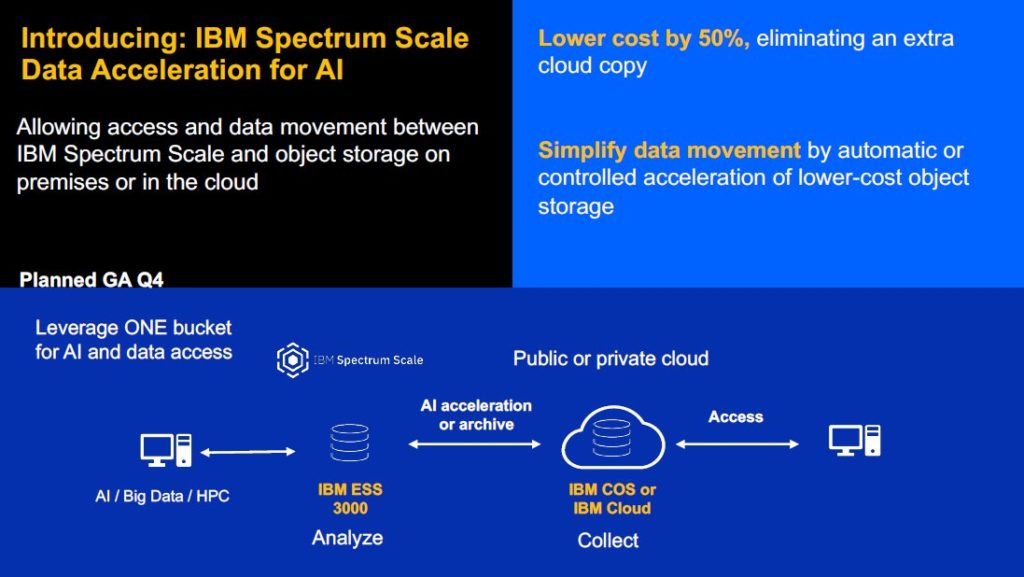
From Q4 2020, IBM Spectrum Scale is getting a new feature, Data Acceleration for AI, which will allow access and automated data movement between Spectrum Scale storage and object storage, whether on-premises or in the cloud. This can effectively allow object storage to become part of the same data lake as the Spectrum Scale system.
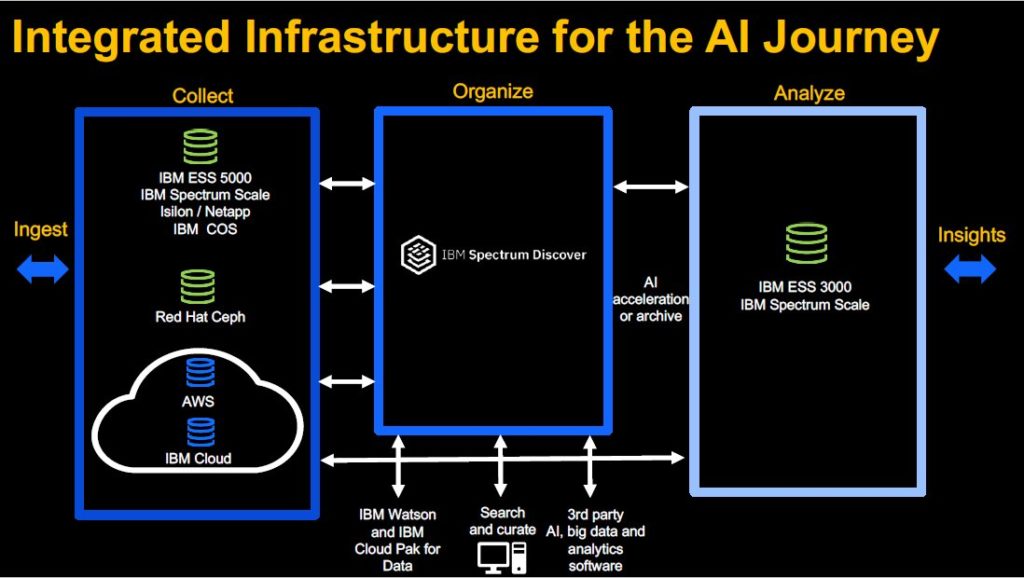
For the Organise stage of the AI pipeline, IBM said that the AI infrastructure has to be capable of supporting continuous, real-time access across multiple storage vendors. Its solution here is IBM Spectrum Discover, providing file and object data cataloguing and indexing, with support for heterogenous data source connections to storage systems from other vendors and from cloud storage.
“We provide Spectrum Discover to collect file and object metadata, and it is able to search billions of records in seconds,” said Herzog.
From Q4 2020, Spectrum Discover will be available in a containerised configuration that can be deployed on Red Hat’s OpenShift application platform, making it easier to deploy in a multi-cloud or hybrid cloud infrastructure.
Also announced and coming in September is an updated Policy Engine for Spectrum Discover that enables customers to set policies to automatically tag and archive old data to lower cost storage, or migrate data to consolidate and lower overall storage costs.
“This provides a real way for customers to manage a very large unstructured data repository,” said Herzog.
IBM said its platforms are interoperable with infrastructure from other vendors, allowing customers to integrate existing storage systems into any of the stages of their AI pipeline if required.





