Analysis: NetApp posted record revenue this quarter, helped by all-flash array sales and public cloud storage demand.
In the fourth fiscal 2025 quarter ended April 25, NetApp reported record revenues of $1.73 billion, up 4 percent on the year. There was a $340 million profit (GAAP net income), 16.8 percent more than a year ago. Its full fy2025 revenues were its highest-ever, at $6.57 billion, 5 percent more than fy2024 revenues, with a profit of $1.2 billion, 20.7 percent up on the year.
George Kurian
Within these low single-digit revenue rises there were some outliers. The all-flash array annual run rate rose to an all-time high of $4.1 billion, up 14 percent. This was faster growth than Pure, which registered a 12.2 percent rise to $778.5 million in its latest results. There was a record (GAAP) operating margin of 20 percent for the full year, record full year billings of $6.78 billion and record first-party and marketplace Public Cloud services revenue of $416 million in the year, up 43 percent annually.
CEO George Kurian stated: “Fiscal Year 2025 marked many revenue and profitability records, driven by significant market share gains in all-flash storage and accelerating growth in our first party and marketplace storage services. …We are starting fiscal year 2026 following a year of market share gains, armed with the strongest portfolio in the company’s history and a differentiated value proposition that addresses customers’ top priorities. Looking ahead, I am confident our continued innovation and market expansion will drive sustainable long-term growth.”
Fy2025 revenues of $6.57 billion beat fy2014’s and fy2013’s $6.33 billion. It’s taken NetApp 11 years to match and beat these high points.
Wissam Jabre has been hired as NetApp’s new CFO, coming from being Western Digital’s CFO before the splitting off of Sandisk. Prior NetApp CFO Mike Berry retired but then joined MongoDB as its CFO.
Quarterly financial summary
Gross margin: 69.5 percent, up 0.2 percent year-over-year
Operating cash flow: $675 million vs year-ago $613 million
Free cash flow: $640 million vs $567 million last year
Cash, cash equivalents, and investments: $3.85 billion vs prior quarter’s $1.52 billion
EPS: $1.65 v $1.37 a year ago
Share repurchases and dividends: $355 million vs prior quarters $306 million
NetApp’s two major business segments are hybrid cloud, with $1.57 billion in revenues for the quarter, up 3.2 percent, and public cloud at $164 million, up 7.9 percent.
NetApp said it increased market share, gaining almost 300 basis points in the all-flash market and almost 1-point in the block storage market in calendar 2024.
Looking ahead Kurian said in the earnings call: “I believe that we’ve now reached an inflection point where the growth of all-flash systems and public cloud services, reinforced by the ongoing development of the AI market, will drive sustained top-line growth. …Looking ahead, we expect these growth drivers, along with our laser focus, prioritized investments, and robust execution, to deliver more company records in fiscal year 2026 and beyond.”
+Comment
A look at NetApp’s revenue history shows that, in the recent past, it has only been able to sustain growth for about two years before declining:
Can it break this pattern moving forward?
It reduced its workforce in April, indicating somewhat starightened trading circumstances. Kurian commented: “The global macro-economic outlook faces mixed signals with a general slowdown in growth, lingering inflation concerns, and a significantly higher level of uncertainty. Looking ahead, we expect some increased spending caution, as well as on-going friction in U.S. Public Sector and EMEA. We are incorporating an appropriate layer of caution in our outlook due to these factors.”
The revenue outlook for the first fy2026 quarter reflects this caution, being $1.53 billion +/- $75 million; an 0.7 percent decrease Y/Y at the mid-point.
Full fy2026 revenues are being guided to $6.75 billion +/-$125 million, and a 2.73 percent on the fy2025 number at the mid-point. It is a rise though, with Kurian saying: “We are currently negotiating sizable AI and data infrastructure modernization deals with multiple large enterprises, which we expect to close later in the year. This gives us confidence in our full-year outlook.”
William Blair analyst Jason Ader thought it was a solid fourth quarter but said the guidance was disappointing. He said: “Management noted that the guidance factors in 1) the impact from the divestiture of the Spot by NetApp business, which contributed roughly $95 million in annual sales; and 2) greater spending caution due to continued macroeconomic uncertainty, including slower growth signals, inflation concerns, tariff risk (albeit modest impact), and ongoing demand friction in the US federal sector (approximately 10 percent of sales) and EMEA region (particularly in the European manufacturing vertical).”
Tape library and systems vendor Spectra Logic announced LTO-10 support across its tape library product set, but IBM’s tape drive shrinks the expected capacity and loses backwards compatibility.
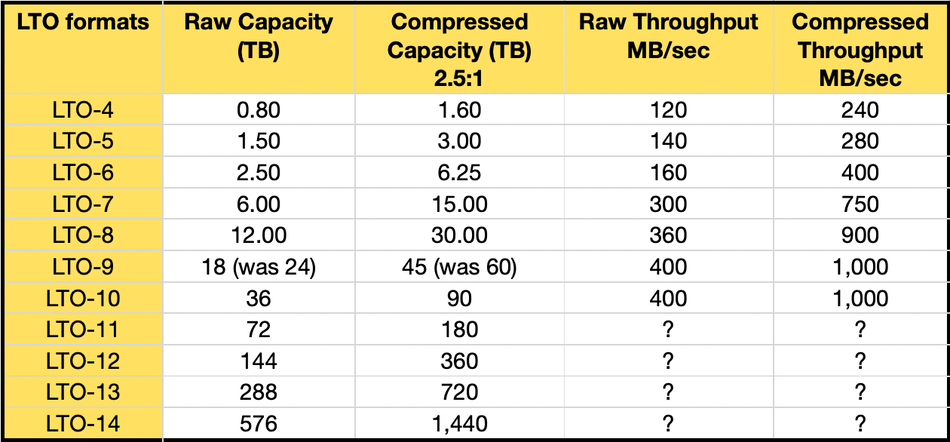
LTO-10 is the latest LTO tape generation and the LTO organization’s spec has specified a 36 TB raw capacity and 90 TB compressed capacity at 2.5:1 compression.
LTO tape reels are made by Fujifilm and Sony and tape drives by IBM. Big Blue’s LTO-10 tape drive only supports 30 TB raw capacity, not 36TB, and so its compressed capacity is 75 TB, while the LTO roadmap provides for “up to” 90 TB.
Big Blue says it “supports the LTO Consortium compressed specification for LTO Ultrium 10, offering up to 75 TB of data storage per cartridge (30 TB native).” It’s possible that the LTO consortium has revised its LTO-10 specification from the published roadmap on its website:
LTO roadmap as of May 28
Spectra’s announcement mentions 30 TB raw capacity per cartridge, which is 66.7 percent capacity growth from LTO-9’s 18 TB but it is 6 TB less than expected.
Spectra says that LTO-10’s transfer speed is 400 MBps raw, the same as the prior LTO-9 generation. So far LTO transfer speeds have increased with each generation.
An increase in throughput depends upon the tape drive reading and writing bit area polarity signals to the tape which are smaller with each generation, and also on the tape’s speed through the drive. Having the same transfer rate as LTO-9 is an abrupt change to the previous consistent speed increase with each LTO generation, as our table shows:
Up until now each successive LTO generation has been backwards-compatible with one and sometimes two previous generations. The LTO organization states that: “LTO specifications for backward compatibility up to generation seven of the technology is to write back one generation and read back two generations. The later 8th and 9th generations of LTO Ultrium tape drives are able to write back and read back one generation.”
IBM says nothing about backward compatibility, with its LTO-10 datasheet simply stating: “IBM LTO 10 tape drive can read and write to LTO Ultrium 10 cartridges.” Translation: there may be no backwards compatibility.
So, with LTO-10, we have not gained as much capacity as hoped, are stuck with the same transfer speed as LTO-9, and very possibly have lost backwards compatibility, all without the LTO organization saying anything about it. We have asked SpectraLogic and the LTO organization about these points. Spectra Logic provided responses to them.
Blocks & Files: Why is Spectra saying LTO-10 has a 30TB raw capacity when the LTO roadmap says LTO-10 has 36TB raw capacity?
Spectra Logic: The LTO roadmap has always said that future generations will be “up to” a certain potential capacity. There have been multiple times where the released capacity does not match with the published LTO forward-looking roadmap, at times exceeding the roadmap capacity as we saw during the LTO-7 release, and at times releasing slightly below the roadmap capacity. The actual capacity for each generation is determined by industry demand and the best and most reliable technologies at the time of release. At 30TB of native capacity per cartridge LTO-10 sets a new baseline for capacity, density, and cost effectiveness for the data storage industry.
Blocks & Files: The LTO-10 bandwidth of 400 MBps raw is exactly the same as that of LTO-9. Why has there been no change in throughput?
Spectra Logic: The LTO-10 technology was prioritized for higher capacity. At 400 MBps native throughput tape is still one of the fastest ways to archive large amounts of data, especially when used in large robotic tape libraries where up to 168 drives can be used in parallel for transfer rates of over 67 GBps. In addition, data throughput can reach up to 1000 MBps on SAS and up to 1200 MBps on FC with compression.
Blocks & Files Is the Spectra LTO-10 drive (IBM’s drive) backwards-compatible with LTO-9 or not?
Spectra Logic: LTO-10 has new technologies that provide advancements for reliability, flexibility, and the future of LTO tape drives. With the advancements, LTO-10 (unlike LTO-9) does not require both media optimization and archive unload. However, there is no method to provide backward media compatibility.
****
Symply told us that the LTO-10 30 TB raw/75 TB compressed capacity will not rise to the LTO roadmap’s maximum of 36 TB raw/90 TB compressed. It said: “The full-height LTO-10 drive has a performance of 400 MB/sec, the same as LTO-9. There are always inevitably going to be design compromises, the performance of the drive could have been increased but that would have had a knock on effect on capacity and other features. The majority consumers of LTO technology are looking for the highest density in the smallest footprint.”
Regarding backwards compatibility it said: “LTO-10 is not backwards compatible with LTO-9. … the drive is almost a completely new design; ASIC, drive head, media formula and loading mechanism. The biggest challenge in increasing capacity on the media, is backwards compatibility. To enable the capacity on LTO-10 and beyond the technology needed to ‘switch tracks’.”
IBM’s LTO-10 drive offers both two Fiber Channel or SAS ports and one Ethernet port. The dual ports allow daisy-chaining a second FC or SAS device. The drives are available in full height and half height form factors.
Spectra is supporting LTO-10 with its TFinity, T950, T950V, T680, T380, T200, Cube, and Stack models. SAS-equipped models are interoperable with the Spectra OSW-2400 Optical SAS Switch. LTO-10 technology is available for immediate ordering and Spectra will offer LTO-10 media at launch. Customers may add LTO-10 drives to any new Spectra library builds or upgrade existing systems using full-height Fibre Channel or SAS drive options. Initial shipments of LTO-10 drives and Certified Media will begin in June 2025.
Tape library manufacturers Symply and Quantum have also announced LTO-10 support, with Symply saying it will be releasing further news over the next few weeks in the run up to GA of the full-height drives.
It is, by the way, the 25th anniversary of the LTO (Linear Tape Open) technology inception, and it looks to be not advancing as fast these days as in previous generational changes.
Bootnote
The LTO organization replied with its answers:
Q1: The LTO Program is still working on capacity improvements for LTO-10 which could rise beyond the current roadmap. These improvements will be announced in due course.
Q2: The LTO-10 technology was prioritized for higher capacity. At 400 MB/s native throughput tape LTO-10 is still one of the fastest ways to archive large amounts of data, and with compression, data throughput can reach up to 1000MBps on SAS and up to 1200MBps on FC.
Q3: No, LTO-10 does not offer backwards compatibility. LTO-10 drives use new recording technology to enable LTO format improvements in the future. One immediate difference is that unlike LTO-9, LTO-10 media does not require initialization or optimization nor archive unload which should improve the user’s day-to-day experience.
Starfish helps companies tap the data value buried in their file systems
Starfish Storage might not be a household name among enterprise storage practitioners, but in high performance computing circles, it is regarded as the most scalable and versatile file management platform. You will find Starfish running in the world’s leading supercomputing centers. These include R&D departments of major corporations, research computing facilities of top universities, simulation farms for EDA, hedge funds, and animation studios.
Versatility and scalability
Starfish tackles a mix of traditional storage management use cases, such as archiving, backup, migration, cost accounting, and aging analytics. It also handles data management use cases including AI/ML workflows, data curation, data preservation, and content classification.
All of this works at an enormous scale. Starfish’s largest customers have thousands of storage volumes, hundreds of petabytes, and tens of billions of files. As a prime example, Starfish was recently deployed at Lawrence Livermore National Laboratory on El Capitan, the world’s most powerful supercomputer.
A data catalog for unstructured data in the wild
Founded in 2011, Starfish was one of the first commercial products to adapt the concept of the data catalog to the navigation and management of files that live out in the wild. By in the wild, we mean those stored on storage devices accessed via NFS, SMB, native clients, POSIX, and S3. These files are in active use. Users, applications, data acquisition devices, scientific and biomedical instruments are constantly adding, deleting, and updating them.
Such files are not housed behind portals such as Microsoft SharePoint and are not part of content management systems, records management systems, archives, or data lakes. They are just like the files on your personal computer. They are subject to renaming, deletion, duplicates, and version mismatches.
Data catalogs are software platforms that associate metadata with data resources such as databases, data lakes, and data warehouses. They enable business users to find and access their institutions’ data assets.
Starfish’s founders saw that the leading data catalog providers lacked the technical means to assign metadata to the unstructured data hiding behind complex directory trees and user permissions. Corporate data catalogs were limited to curating structured and semi-structured data while files in the wild remained opaque and untamed. Starfish’s original product, now called the Unstructured Data Catalog or UDC, addressed this gap in the market by creating an index across all of the organization’s file storage devices that associated metadata with files and directories. The UDC enables the business to understand how file contents relate to projects, intellectual property, workflows, and cost centers even when spread across multiple storage devices.
The UDC helps to solve the age-old problem of linking data storage to data value. It also provides insights into how best to manage storage over time, including what administrators can archive or delete, what they must preserve, and who pays for what. An embedded reporting dashboard shows capacity and aging analytics with fine-grained insights enabled by the metadata system.
The role of the data catalog in AI readiness
Fast-forward to 2025. Organizations of all shapes and sizes are scrambling to become AI-ready by identifying and gaining access to data resources that could be relevant for AI workloads.
This AI/ML frenzy is highlighting the need for data cataloging, especially for the mountains of valuable information buried in an organization’s file stores. AI data quality and security depends upon differentiating file versions, accounting for permissions (particularly in retrieval-augmented generation (RAG) scenarios), and integrating outputs from AI/ML workflows back into the catalog’s metadata.
Enter the copycats
As one might expect new players are entering the field of unstructured data cataloging. Some are startups, while others are traditional storage vendors who are adding data cataloging features into their file storage products. This begs the question: What makes a great file-based data catalog?
One of the essential design criteria for Starfish was to be storage vendor-agnostic. It works with virtually all file and object storage devices. This allows Starfish to have a universal map of all file content stored in the organization. By contrast, a data catalog from a storage vendor is likely to work well with its own storage but not extend itself to content stored in devices from other vendors. The result is simply a new form of vendor lock-in. Starfish bypasses this problem, offering an unobstructed view across all storage devices.
Many data management systems are in-line, meaning they operate directly on the storage infrastructure. This risks bottlenecks and vulnerabilities at scale. Starfish, on the other hand, was designed from the ground up to operate out-of-band, interacting with the storage system from a separate process. This offers advantages like non-disruptive operation and easier scalability.
Engaging end users who understand both the data and its value
Starfish has a feature called Storage Zones that groups related content together and presents it to the relevant users, like researchers, lab managers, librarians, and others. It gives them tools for searching and tagging within the boundary of their zone. This enables storage users to manage their file collections, even if they are spread across multiple systems including NAS, HPC file systems, and S3 buckets.This is yet another advantage of being storage agnostic; The feature lets those who best understand the value of their data engage in data management practices. In the long term, the results add up, as organizations can store data in ways that better reflect its value while freeing primary storage.
The need for data movement and data processing
A data catalog’s metadata and discovery capabilities are only half the picture, whether you seek to be AI ready or to tackle some other aspect of unstructured data management. There must also be a mechanism to enable files of interest to be accessed and processed in secure ways.
Starfish incorporates a jobs engine called the Starfish Automation Engine that can process and move files based on insights from the catalog. In turn, the jobs engine adds metadata to the catalog based on discoveries made or actions taken by the jobs engine.
The catalog might identify files that should be used to train a model. The jobs engine could then submit the files to the training pipeline and record back into the metadata catalog which versions of which files were used to train the model. Over time, this feedback loop gives you a deeper understanding of how you are using and managing your data sets.
In summary
These are exciting times for Starfish Storage. The niche we’ve occupied for over a decade is going mainstream and we have a unique, mature solution that works at the top end of scale.
Alongside a unified file indexing system that spans multiple vendors’ storage devices, we have a flexible metadata system that makes it easy to classify, move, and process file collections. Contact starfishstorage.com to learn more. If you are attending ISC in Hamburg, Germany, come see us at Booth A22 June 10-13. Qualified customers are welcome to trial Starfish in their own environment free of charge. You will learn a lot about your file storage in such a trial.
Nutanix enjoyed a classic beat-and-raise results pattern in its latest quarterly earnings report.
Revenues in hyperconverged infrastructure software supplier Nutanix’s third fiscal 2025 quarter, ended April 30, were $637 million, beating its $630 million high-point estimate, and up 22 percent year-on-year. It reported $63.4 million of net profit (GAAP net income), roundly beating the year-ago $15.6 million loss.
Rajiv Ramaswami.
President and CEO Rajiv Ramaswami, said: “We delivered solid third quarter results, above the high end of our guided ranges, driven by the strength of the Nutanix Cloud Platform and demand from businesses looking for a trusted long-term partner.”
Financial summary:
ARR: $2.14 billion, up 18 percent
Gross margin: 87 percent , up 2.2 percent year-on-year
Free cash flow: $203.4 million vs year-ago $78.3 million
Operating cash flow: $218.5 million vs $96.4 million last year
Cash, cash equivalents, and short-term investments: $1.88 billion compared to $1.74 billion in the prior quarter.
Ramaswami noted in the earnings call that: “We exceeded all our guided metrics. … Our largest wins in the quarter demonstrated our ability to land and expand within some of the largest and most demanding organizations in the world as they look to modernize their IT footprints, including adopting hybrid multi-cloud operating models and modern applications, as well as those looking for alternatives in the wake of industry M&A.”
That last point was a thinly veiled reference to Broadcom raising prices at VMware, which it bought it boguht for $61 billion in 2022. Nutanix said that its business with the tier 2 Cloud Service Providers and MSPS, which has not been a focus before, is now picking up as these customers are looking for an alternative to VMware.
Ramaswami said: “We do think that that market actually for us represents a significant opportunity, given the big vacuum that’s out there now with VMware.” Nutanix has added some specific CSP and MSP programs, as well as product multi-tenancy, to grow this side business which was historically small for it. The European CSP sovereign cloud market is another CSP opportunity
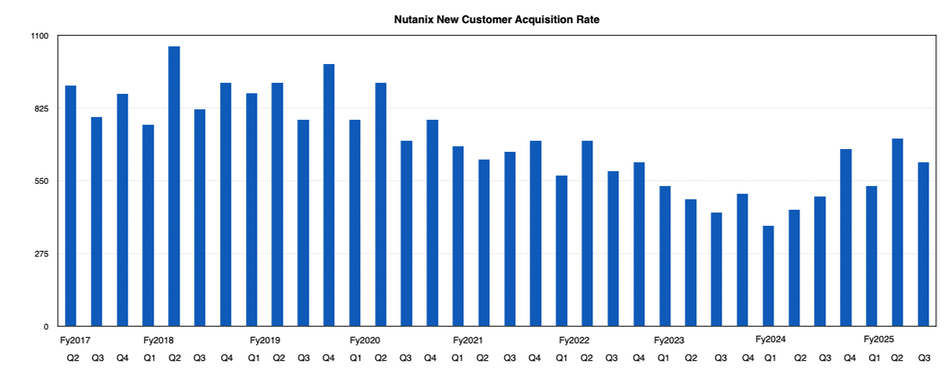
Nutanix gained 620 new customers in the quarter, taking its total to 28,490. There has been a notable pick up in its new customer acquisition rate from a low point of 380 six quarters ago;
CFO Rukmini Sivaraman said in the earnings call: “We continue to see strength in landing new customers onto our platform from the various programs we have put in place to incentivize new logos from a general increase in engagement from customers, looking at us as an alternative in the wake of industry M&A, and helped by more leverage from our OEM and channel partners.”
Ramaswami noted Cisco has been a consistent contributor of new logos to Nutanix: “it’s still a minority contribution, but a steady contribution to our new logo growth.”
After announcing external storage sales agreements with Dell and Pure Storage in the quarter, Ramaswami said Nutanix is: “expanding our cloud platform to support Google Cloud, which will be in early access this summer.”
He added: “Our customers would like us to support every external storage array that’s out there. They want to see how we can make migration as easy as possible for them.”
Although Nutanix is an HCI company, much of the market consists of 3-tier users with external storage. Ramaswami recognizes this: “that’s really the reason why, from our perspective, it makes sense to go broader and think of ourselves as not just a HCI provider anymore, but now a platform company. And as a platform, you support a broad ecosystem around you. So you can have external storage or you can have our own storage.”
Nutanix is ramping up its sales and marketing headcount to pursue market opportunities, such as 3-tier enteroprise customers, VMware switchers, tier 2 CSPs and MSPs and sovereign clouds.
Note the Q3 fy2025 acceleration compared to Q2 and Q1 fy2025.
Asked about tariff impact Sivaramen said: “We don’t have a direct exposure to tariffs, and we haven’t seen an impact from tariffs to date.”
For the next quarter Nutanix assumes that the macro and demand environment will remain similar to what it saw in Q3. It expects to continue to add new customers, while noting that a strong performance in Q4 of its previous financial year presents a tough year-over-year comparison for new logo additions, when it added 670 new customers.
One problem is the US federal market where there are lots of personnel changes and additional reviews, meaning somewhat longer deal cycles and some variability across the Fed business. Longer term though, Nutanix is optimistic about its Fed business as the Feds need to modernize their IT and reduce total cost of ownership.
Next quarter’s revenue outlook is $640 million ± $5 million, a 16.8 percent uplift on the year-ago Q4. It has increased its full year fy2025 revenue guidance to $2.525 billion from the previous guidance of $2.505 billion.
MinIO is supporting AWS’s fastest S3 storage tier to offer object data access for AI and data-intensive analytics workloads.
S3 Express One Zone has a 10x lower latency to first byte compared to the standard S3 offering. It comes at a price, costing nearly five times more at $0.11/GB/month than S3 Standard’s $0.023 for the first 50 TB/month. MinIO says this fastest AWS S3 service doesn’t come with data protection and replication capabilities and says customers need to “save a durable copy of their data in S3 standard and copy data that requires high speed access into S3 Express One Zone.”
MinIO is announcing AIStor support for the S3 Express API and “coupling its dramatic performance advantages with full active/passive, disaster recovery (DR), and batch replication support, all at no extra cost.”
AIStor is the MinIO object storage offering that supports Nvidia’s RDMA-based GPUDirect for object storage, BlueField-3 DPUs and NIM Microservices and agent MCP connectivity.
Garima Kapoor
Garima Kapoor, MinIO co-founder and co-CEO, said in a statement: “With the AIStor S3 Express API, pricing remains the same so enterprises can now put all of their analytical and AI data, not just a subset, in ‘express mode.’ This is drawing tremendous excitement from customers.”
There are no request charges for GETs, PUTs and LISTs with MinIO’s S3 Express API support, and according to the vendor, it features:
Accelerated PUT and LIST operations with up to 20 percent faster PUT operations, lowering CPU utilization, and up to 447 percent faster time-to-first-byte (TTFB) LIST operations relative to AIStor general purpose S3 API. It says this means faster training, faster analytics, and better infrastructure utilization.
New atomic, exclusive append operations enabling direct and safe object modification, eliminating multi-step update workflows. For example, media-broadcasting applications which add new video segments to video files can do so as they are transcoded and immediately streamed to viewers.
Full active/passive, disaster recovery (DR), and batch replication support with synchronous replication meaning no data loss in the event of an outage, and asynchronous replication enabling data protection across the globe.
Streamlined and simplified API behavior to improve the developer experience, application resiliency, predictability and security.
Pure Storage’s first quarter revenues rose in double digits with no signs of order pull-ins from tariff uncertainity.
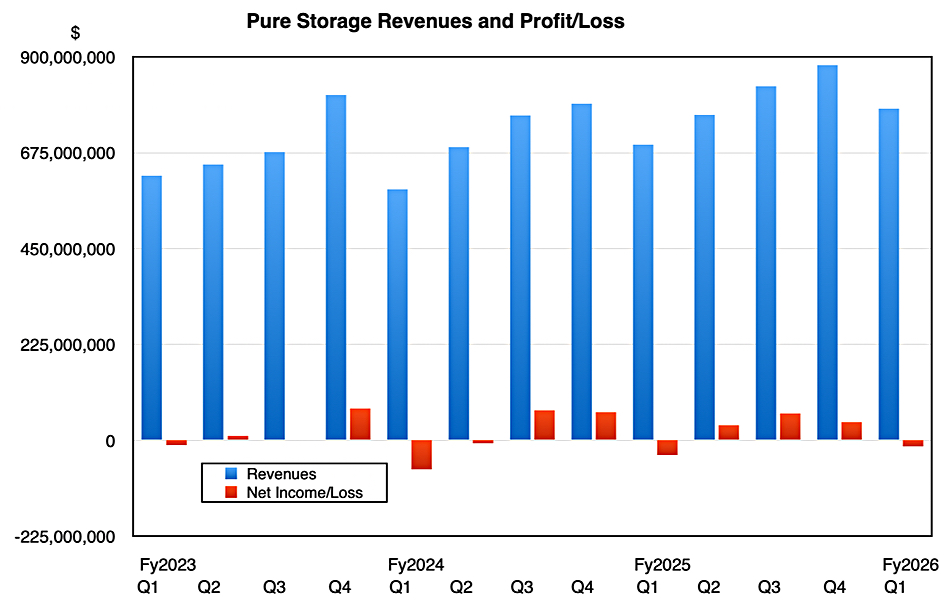
Revenues grew 12 percent year-on-year to $778.5 million in the quarter ended May 4, beating the $770 million outlook. Pure reported a net loss of $13.9 million, better than the year-ago $35 million loss. This is in line with seasonal trends – Pure has made a loss in its Q1 for three consecutive years while making profits in the other quarters, as the below chart indicates:
CEO Charlie Giancarlo said the business experienced “steady growth”.
”Pure delivered solid performance in Q1, delivering double digit growth within a dynamic macro environment.” There were: “very strong Evergreen//One and Evergreen//Forever sales” in the quarter. Evergreen//One is a storage-as-a-service while Evergreen//Forever is a traditional storage offering with continuous HW and SW upgrades via subscription.
Financial summary:
Gross margin: 68.9 percent, down from 73.9 percent a year ago
Free cash flow: $211.6 million vs $173 million a year ago
Operating cash flow: $283.9 million vs $221.5 million a year ago
Total cash, cash equivalents, and marketable securities: $1.6 billion vs $1.72 billion a year ago
Remaining Performance Obligations: $2.69 billion, up 17 percent year-on-year
The hyperscale business is progressing but not delivering revenue increases yet. Giancarlo said in the earnings call: “Our hyperscale collaboration with Meta continues to advance. Production validation testing is on schedule with strong progress in certifying our solutions across multiple performance tiers. We remain on track to deliver our anticipated 1-2 exabytes of this solution in the second half of the year, as planned.”
This would be revenue on a license fee model, not on full product sales. Getting revenues from these projects takes time, Giancarlo said: ”The reason is because it’s not the testing of our product specifically that’s taking a long time. It is their design cycle of their next-generation data center, which goes well beyond just the storage components of it.”
He added: “It generally takes us somewhere between 18-months and two years to design a new product here at Pure. It’s the same for these hyperscalers who are designing their next-generation data center.” It’s a co-engineering process.
Giancarlo said Pure is working well with the other hyperscalers: “We’re making steady progress there [at] about the pace that we expected. Hard to predict when one of those would turn into what we would call a fully validated design win. We are in some POCs [proof of concept] that should be an indicator. …we think we’re on track, but there’s still more work to be done before we can declare victory.”
Pure confirmed CFO Kevan Krysler is leaving for a new opportunity, and will stay in place until a new CFO is appointed.
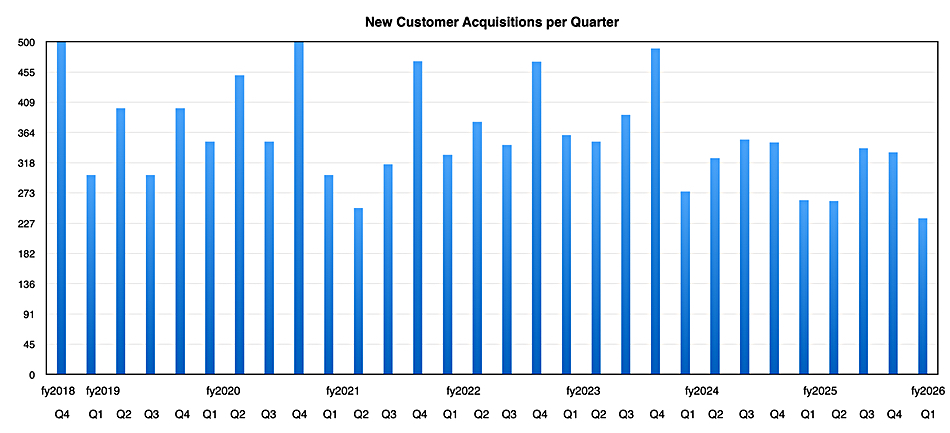
New customer additions in the quarter totalled 235, the lowest increase for seven years.
Next quarter’s outlook is for $845 million in revenues, a 10.6 percent year-on-year rise, with a $3.5 billion full year revenue forecasted, equating to a rise of 11 percent. Giancarlo said: ”Our near-term view for the year remains largely unchanged, although we are navigating increased uncertainty.” Overall: “We are confident in our continued momentum to grow market share and strengthen our leadership in data storage and management.”
Pure will announce a new products at its forthcoming Accelerate conference – June 17 – 19, Las Vegas – to enable customers “to create their own enterprise data cloud, allowing them to focus more on their business outcomes rather than their infrastructure.”
Analyst Jason Ader told subscribers: “We believe that Pure Storage will steadily take share in the roughly $35+ billion enterpise storage market based on: 1) clear product differentiation (as evidenced by industry-leading gross margins); 2) strong GTM organization and deep channel partnerships; 3) secular trend toward all-flash arrays (AFAs), in which Pure has been a pioneer; and 4) Pure’s leverage to robust spending areas, including SaaS data centers, HPC, and AI/ML use-cases.”
Alluxio, supplier of open source virtual distributed file systems, announced Alluxio Enterprise AI 3.6. This delivers capabilities for model distribution, model training checkpoint writing optimization, and enhanced multi-tenancy support. It can, we’re told, accelerate AI model deployment cycles, reduce training time, and ensure data access across cloud environments. The new release uses Alluxio Distributed Cache to accelerate model distribution workloads; by placing the cache in each region, model files need only be copied from the Model Repository to the Alluxio Distributed Cache once per region rather than once per server. V 3.6 debuts the new ASYNC write mode, delivering up to 9GB/s write throughput in 100 Gbps network environments. There is a web-based Management Console designed to enhance observability and simplify administration. It has multi-tenancy support, multi-availability zone failover support and virtual path support in FUSE.
…
AWS announced GA of Aurora DSQL, a serverless, distributed SQL database enabling customers to create databases with the high availability, multi-Region strong consistency, and PostgreSQL compatibility. Until now, customers building globally distributed applications faced difficult trade-offs when selecting a database: Existing systems offered either low latency without strong consistency, or strong consistency with high latency, but never both low latency and strong consistency in a highly available SQL database. With Aurora DSQL, AWS claims customers no longer need to make these trade-offs. It’s now GA in eight AWS Regions, with availability in additional regions coming soon.
…
Fervent AI-adoptee Box announced revenue of $276 million, up 4 percent Y/Y for its Q1 fy2026 quarter with $3.5 million net income. Billings came in at $242.3 million, up 27 percent. Next quarter’s revenue is expected to be $290 million to $291 million, up 8 percent Y/Y. Aaron Levie, co-founder and CEO of Box, claimed: “We are at a pivotal moment in history where AI is revolutionizing work and business. In this AI-first era, organizations are embracing this shift to stay competitive… Earlier this month, we unveiled our largest set of AI innovation yet, including new AI Agents that integrate with the leading models and software platforms to accelerate decision-making, automate workflows, and boost productivity.”
…
Cloudera announced an extension of its Data Visualization capability to on-premises environments. Features include:
Out-of-the-Box Imaging: Drag-and drop functions which facilitate graph and chart creation for use cases ranging from customer loyalty shifts to trading trends.
Built-in AI: Unlock visual and structured reports with natural language querying thanks to AI Visual.
Predictive Application Builder: Create applications pre-built with machine learning models served by Cloudera AI, as well as Amazon Bedrock, OpenAI and Microsoft Azure OpenAI.
Enterprise Security: use enterprise data from anywhere without moving, copying or creating security gaps as part of the Cloudera Shared Data Experience (SDX).
Robust Governance: Gain complete control over data used for picturing with advanced governance features.
…
Datadobi took part in the in the SNIA Cloud Object Storage Plugfest, sponsored by CST, at the end of April in Denver. It says: “we explored emerging challenges in cloud object storage around the AWS S3 protocol, where continuous server-side changes, evolving APIs and fragmented third-party implementations often lead to compatibility issues. Plugfest allowed us to brainstorm, plan, run compatibility tests, experiment, and work collectively on addressing these pain points.”
…
DataOps.live announced the launch of the Dynamic Suite, which includes two new Snowflake Native Apps designed to solve data engineering challenges faced by many Snowflake customers: continuous integration and deployment (CI/CD) of Snowflake Objects, and the operationalization of dbt projects. The Dynamic Suite of Snowflake Native Apps are available on the Snowflake Marketplace. They are the first two deliverables of the Dynamic Suite family, with additional ones to follow.
…
HighPoint Technologies is introducing a portable, near-petabyte NVMe table-top, storage product with 8 x Solidigm D5-P5336 122TB SSDs in a RocketStor 6542AW NVMe RAID Enclosure to deliver 976TB storage capacity in a compact box. Highpoint says it’s designed to provide scalable, server-grade NVMe storage for a variety of data-intensive applications, including AI, media production, big data analytics, enterprise data backup, and HPC.
RocketStor 6542AW
…
MariaDB is acquiring Codership and its flagship product Galera Cluster, an open-source, high-availability database. This marks the next chapter in a long-standing relationship between MariaDB and Codership as, for over a decade, Codership’s technology has been integrated into MariaDB’s core platform. As such, this deal is expected to come with no disruption to service. It says that, with the Galera team now formally onboard, MariaDB will accelerate development of new features for high availability and scalability across the Enterprise Platform. Galera Cluster is becoming a more integral part of the platform, enabling a more seamless and robust customer experience going forward. Customers will gain access to deeper expertise and more responsive support for database needs directly from the team behind Galera.
…
At Taiwan’s Computex Phison showed new hardware:
Pascari X200Z Enterprise SSD: engineered for endurance (up to 60 DWPD) and SCM-like responsiveness, the new X200Z is designed to provide enterprise-grade performance for AI, analytics, and database workloads. It’s Phison’s most advanced Gen5 SSD for write-intensive environments to date.
aiDAPTIVGPT: a plug-and-play inference services suite for on-premises LLMs. It offers conversational AI, code generation, voice services, and more. It fills a critical market gap for SMBs, universities, and government agencies seekinglocalized AI performance without public cloud dependencies.
E28 SSD Controller: the E28 is Phison’s flagship PCIe Gen5 SSD controller, now with integrated AI compute acceleration for faster model updates and unmatched Gen5 performance.
…
Researchers from Pinecone, University of Glasgow and University of Pisa recently published “Efficient Constant-Space Multi-Vector Retrieval,” introducing “ConstBERT” – an approach that reduces the storage requirements of multi-vector retrieval by ~50% through fixed-size document representations. We’re told that ConstBERT reduces memory and compute cost while retaining strong retrieval quality. For most practical applications, especially those involving large-scale candidate reranking, it offers no meaningful compromise in quality but substantial gains in efficiency. As AI applications increasingly rely on effective retrieval for accuracy (particularly RAG systems), this approach offers a promising direction for deploying efficient retrieval at scale.
The paper’s abstract says: “Multi-vector retrieval methods, exemplified by the ColBERT architecture, have shown substantial promise for retrieval by providing strong trade-offs in terms of retrieval latency and effectiveness. However, they come at a high cost in terms of storage since a (potentially compressed) vector needs to be stored for every token in the input collection. To overcome this issue, we propose encoding documents to a fixed number of vectors, which are no longer necessarily tied to the input tokens. Beyond reducing the storage costs, our approach has the advantage that document representations become a fixed size on disk, allowing for better OS paging management. Through experiments using the MSMARCO passage corpus and BEIR with the ColBERT-v2 architecture, a representative multi-vector ranking model architecture, we find that passages can be effectively encoded into a fixed number of vectors while retaining most of the original effectiveness.”
…
Pure Storage is partnering SK hynix “to deliver state-of-the-art QLC flash storage products that meet the high-capacity, energy efficient requirements for data-intensive hyperscaler environments.” SK hynix recently announced a 60TB-class PS1012 SSD and says it will develop 122TB and 244TB follow-on drives to meet AI storage demand. The 60 TB and 122TB drives uses SK hynix’ 238-layer 3D NAND while the 256TB one will use newer 321-layer 3D NAND.
Pure says it can deliver future DirectFlash Module products with SK hynix’s QLC NAND flash memory that will be purpose-built for demanding hyperscaler environments. Pure also has agreements with Micron and Kioxia for NAND chips.
…
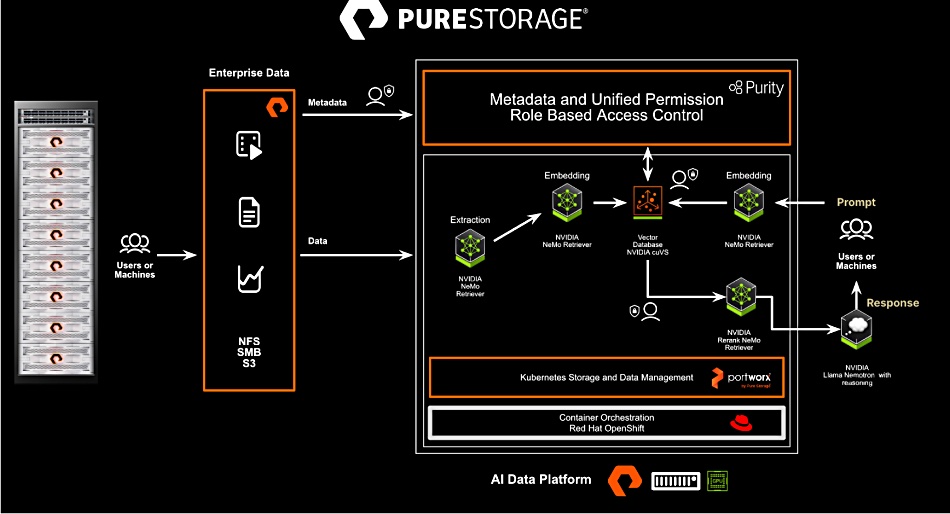
Pure Storageblogs about its latest support for Nvidia, saying the NVIDIA AI Data Platform reference design has been implemented with FlashBlade//EXA and Portworx. It says “By leveraging accelerated compute through NVIDIA Blackwell, NVIDIA networking, retrieval-augmented generation (RAG) software, including NVIDIA NeMo Retriever microservices and the AI-Q NVIDIA Blueprint, and the metadata-optimized architecture of Pure Storage, organizations reduce time to insight from days to seconds while maintaining very high inference accuracy in production environments.”
…
Quantum announced a major refresh of its Professional Services portfolio, including:
Subscription-Based Value Packages – Combining Quantum’s training, updates, guidance, and more at up to 40 percent savings.
Deployment Services – Installation and configuration support from certified Quantum experts
On-Demand Services – Commitment-free support that includes health checks, workflow integration, system migration (including non-Quantum environments) to optimize hybrid and cloud storage setups.
…
Rubrik and Rackspace Technology have launched Rackspace Cyber Recovery Service, a new fully-managed service aimed at improving cyber resilience for businesses operating in the public cloud. By integrating Rubrik’s data protection and recovery technologies with Rackspace’s DevOps expertise, the service is intended to help organizations recover from ransomware attacks.
Accelerated and automated recovery: Enables restoration of cloud workloads using orchestrated, codified workflows and DevOps best practices.
Enhanced cyber resilience: Combines immutable backups, zero-trust architecture, and AI-driven threat detection to ensure data recovery.
Fully Managed end-to-end support: Offers professional services, continuous optimisation, and guidance for policy management, compliance, and infrastructure recovery.
…
Singularity Hub published an article about molecular plastic storage as an alternative to DNA storage. It said: “a team from the University of Texas at Austin took a page from the DNA storage playbook. The researchers developed synthetic molecules that act as ‘letters’ to store data inside custom molecules. Compared to DNA sequences, these molecular letters are read using their unique electrical signals with minimal additional hardware. This means they can be seamlessly integrated into existing electronic circuits in our computers.” Read the piece here.
…
Symply announced LTO-10 products with up to 30TB uncompressed and 75TB compressed per cartridge and a native performance of up to 400MB/Sec. CEO Keith Warburton said: “LTO-10 is a sea change in technology with a completely new design, including new head technology, and new media substrate.” The three new products are:
SymplyPRO Ethernet–Desktop and Rackmount standalone LTO drives with 10Gb Ethernet connectivity.
SymplyPRO Thunderbolt–Desktop and Rackmount standalone LTO drives with Thunderbolt & SAS connectivity.
SymplyPRO XTL 40 and 80– Mid-range and Enterprise modular tape libraries featuring SAS, Fibre Channel, Ethernet, and Thunderbolt interfaces.
The products will begin shipping in mid-June 2025 and are compatible with media and entertainment backup and archive software applications such as Archiware, Hedge and YoYotta. Initially available in standalone desktop and rackmount formats with Ethernet, SAS, and Thunderbolt interfaces. The SymplyPRO XTL 40 and 80 slot modular libraries will follow later in Q4 2025, featuring interoperability with enterprise backup and archive applications.
Simply desktop and rack mount LTO-10 tape libraries.
Pricing: SymplyPRO XTL 80 Library from $26,995, SymplyPRO SAS LTO-10 from $11,995, SymplyPRO Ethernet LTO-10 from $15,995, SymplyPRO Thunderbolt LTO-10 from $12,995and SymplyPRO XTL 40 Library from $19,995 .
…
Synology’s PAS7700 is an active-active NVMe all-flash storage product. Combining active-active dual-controllers with 48 NVMe SSD bays in a 4U chassis, PAS7700 scales to 1.65 PB of raw capacity with the addition of 7 expansion units. Synology says it uses an all NVMe array to deliver millisecond-grade low latency and up to 2 million IOPS and 30GB/s sequential throughput, and supports a range of file and block protocols including SMB, NFSv3/4 (including RDMA versions), iSCSI, Fibre Channel, NVMe-oF TCP, NVMe-FC, and NVMe-RoCE. It features redundant memory that is upgradable to 2,048 GB across both controllers (1,024 GB per node) and support for high-speed 100GbE networking. It offers immutable snapshots, advanced replication and offsite tiering.
Synology PAS7700.
…
Yugabyte is supporting DocumentDB, Microsoft’s document database-compatible Postgres extension. By bringing NoSQL workloads on PostgreSQL, Yugabyte claims it is both reducing database sprawl and providing developers with more flexibility to replace MongoDB workloads with YugabyteDB – this means they can avoid vendor lock-in issues and take advantage of advanced vector search capabilities needed to build next-generation AI applications.
Hitachi has worked to re-evaluate the fit of its Hitachi Vantara subsidiary to respond faster to the market’s adoption of AI and AI’s accelerating development, according to its Chief Technology Officer.
In late 2023 Hitachi Vantara was reorganized with a services unit spun-off, a new direction set, and Sheila Rohra taking control as CEO.
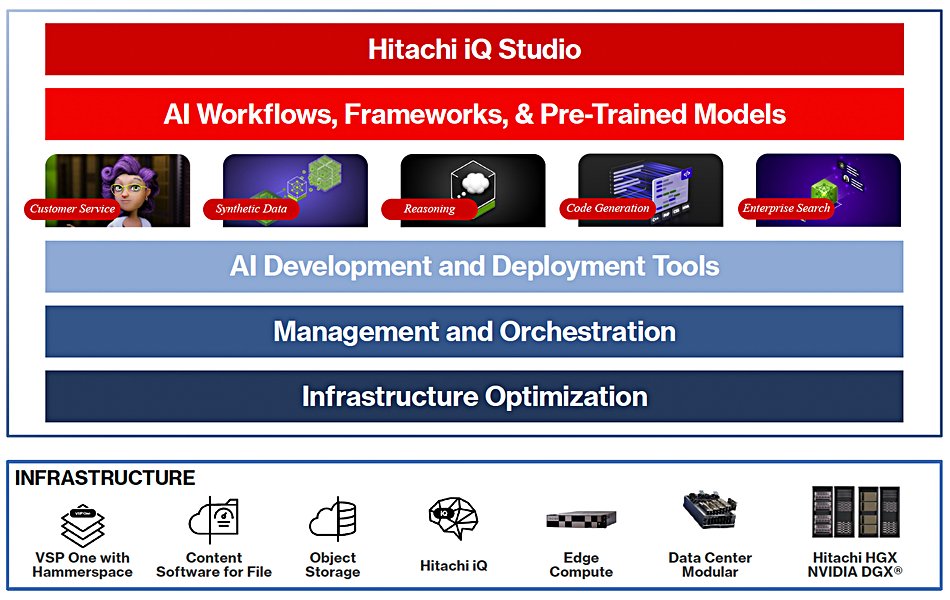
It built a unified storage product data plane, a unified product control plane and an integrated data-to-agent AI capability. VSP One, the unified data plane, was launched in April last year and all-QLC flash and object storage products added late in the 2024. The unified control plane VSP 360 was announced a week ago. The soup-to-nuts AI capability is branded Hitachi iQ, not VSP One iQ nor Hitachi Vantara iQ, as it will be applied across the Hitachi group’s product portfolio.
Jason Hardy
Jason Hardy, Hitachi Vantara’s CTO for AI and a VP, presented Hitachi iQ at an event in Hitachi Vantara’s office.
VSP One
The data plane includes block, file and object protocols as well as mainframe storage. VSP One includes separate products for these, with:
VSP Object – the HCP (Hitachi Content Platform) product
A new VSP Object product is coming later this year, S3-based, developed in-house by Hitachi Vantara, and set to replace the existing HCP-based object storage product, which will be retired.
Hitachi Vantara is also unifying VSP One file and object with its own on-house development. This started a year ago. Up until now there has been no demand to unify block with file and object.
The data plane is hybrid, covering the on-premises world and will use the three main public clouds: AWS, Azure and GCP (Google Cloud Platform). The current public cloud support status is:
VSP One SDS Block – available on AWS and GCP with Azure coming
VSP One SDS Cloud – available on AWS
VSP One File – roadmap item for AWS, Azure and GCP
VSP One Object – roadmap item for AWS, Azure and GCP
VSP 360
The recently announced VSP 360 single control plane is an update or redevelopment of the existing Ops Center, and will play a key role in how AI facilities in the business are set up to use VSP One and how they are instantiated.
VSP 360 gives observability of and insight into VSP One’s carbon footprint. This is read-only now. The next generation of the product will enable user action. A user could, for example, choose a more sustainable option if VSP 360 reveals that the footprint is getting high and alternatives are available. This will be driven by agentic AI capabilities, implying that more than one agent will be involved and the interaction between the agents cannot be pre-programmed.
The VSP One integrated and hybrid storage offerings, managed, observed and provisioned through VSP 360, form the underlying data layer used by Hitachi iQ.
Hitachi iQ
Hitachi Vantara says it has been working with Nvidia on several projects, including engagements with Hitachi group businesses such as Rail where an HMAX digital asset management system, using Nvidia GPUs in its IGX industrial AI platform, has – we’re told – enabled a 15 percent lowering of maintenance costs and a 20 percent reduction in train delays. Hitachi Vantara also has an Nvidia BasePOD certification. A blog by Hardy provides some background here.
Hitachi Vantara featured in Jensen Huang’s agentic AI pitch at Computex as an AI infrastructure player along with Cisco, Dell, HPE, Lenovo, and NetApp
Hitachi Vantara says its iQ product set is developing so fast that the marketing aspect – ie, telling the world about it – has been a tad neglected.
Hardy told B&F that Hitachi iQ is built on 3 pillars: Foundation, Enrichment and Innovation. The Foundation has requirements aligned with Nvidia and Cisco and is an end-to-end offering equivalent to an AI Factory for rapid deployment. Enrichment refers to additional functionality, advisory services and varied consumption models. A Hammerspace partnership extends the data management capabilities, a WEKA deal provides high-performance parallel file capabilities, and the data lake side is helped with a Zetaris collaboration. Innovation refers to vertical market initiatives, such as Hitachi iQ AI Solutions use case documentation, and projects with partners and Nvidia customers.
A Hitachi iQ Studio offering is presented as a complete AI solution stack spanning infrastructure to applications and running across on-prem, cloud, and edge locations. It comprises an iQ Studio Agent and Studio Agent runtime with links to Nvidia’s NIM and NeMO Retriever microservices extracting and embedding data from VSP One object and file, and storing the vectors in a Milvus vector database.
There is a Time Machine feature in iQ which is, we understand, unique to Hitachi V and developed in-house. This enables the set of vectors used by a running AI training or inference job to be modified, during the job’s execution and without topping the job.
As we understand it, incoming data is detected by iQ and embedding models run to vectorize it, with the vectors stored in a Milvus database. The embedding is done in such a way as to reserve, in metadata vectors, the structure of incoming data. For example, if a document file arrives, this has content and file-level metadata; author, size, date and time created, name, etc. The content is vectorized as is the metadata so that the vectorized document entity status is stored in the Milvus database as well.
Hitachi iQ Studio components graphic
This means that if, for some reason, a set of vectors which includes the content ones from the document becomes invalid during the AI inference or training run, because the document breaks a privacy rule, the document content vectors can be identified and removed from the run’s vector set in a roll back type procedure. That’s why this feature is called a Time Machine – note the time metadata notes in the iQ Studio graphic above.
What we’re taking away from this is that Hitachi iQ product set is moving the company into AI storage and agentic work, hooking up with Nvidia, joining players such as Cisco, Dell, HPE, Lenovo, NetApp and Pure Storage. It’s done this by a combo of partnering and in-house development, leaving behind its previous (Hitachi Data Systems) acquisition mindset – remember the Archivas, BlueArc, Cofio, ParaScale, Pentaho and Shoden Data Systems purchases?
Hitachi V is in a hurry and AI is its perceived route to growth, increased relevance and front rank storage system supplier status. It is hoping the iQ product range will give it that boost.
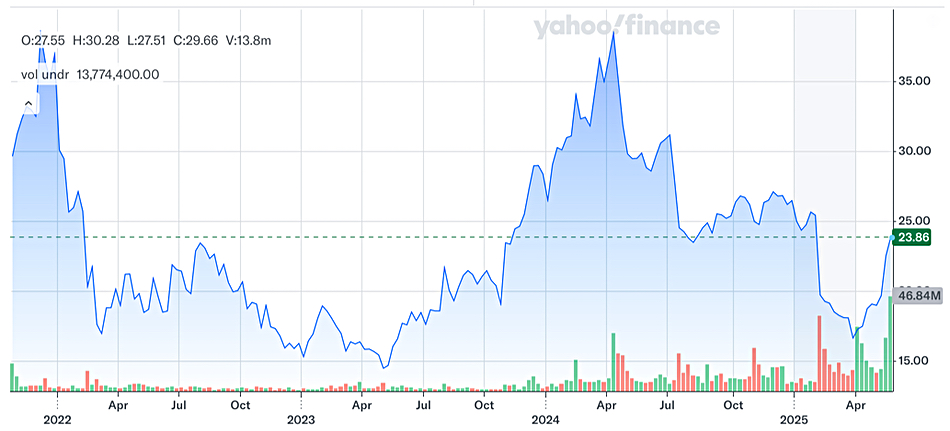
SaaS giant Salesforce is entering into an agreement to buy data integrator and manager Informatica in a bid to strengthen its Agentforce’s data credentials, paying $25/share (totalling around $8 billion). Informatica’s current stock price is $23.86.
Salesforce says buying Informatica will give it a stronger trusted data foundation needed for deploying “powerful and responsible agentic AI.” It wants its Agentforce agents to work at scale across a customer’s Salesforce data estate. Salesforce has a unified data model and will use Informatica tech to provide a data catalog, integration and data lineage, plus data quality controls, policy management and master data management (MDM) features.
Marc Benioff.
Marc Benioff, Chair and CEO of Salesforce, said: “Together, Salesforce and Informatica will create the most complete, agent-ready data platform in the industry. By uniting the power of Data Cloud, MuleSoft, and Tableau with Informatica’s industry-leading, advanced data management capabilities, we will enable autonomous agents to deliver smarter, safer, and more scalable outcomes for every company, and significantly strengthen our position in the $150 billion-plus enterprise data market.”
Salesforce claims that buying Informatica will:
Strengthen Data Cloud’s leadership as a Customer Data Platform (CDP), ensuring data from across the organization is not just unified but clear, trusted, and actionable.
Provide a foundation for Agentforce’s autonomous AI agents to interpret and act on complex enterprise data, building a system of intelligence.
Salesforce CRM applications will be enhanced, giving customer teams the confidence to deliver more personalized customer experiences.
Informatica’s data quality, integration, cataloging, and governance will ensure data flowing through MuleSoft APIs is connected and also standardized.
Tableau users will benefit from richer, context-driven insights through access to a more accessible and better-understood data landscape.
Salesforce CTO Steve Fisher said: “Truly autonomous, trustworthy AI agents need the most comprehensive understanding of their data. The combination of Informatica’s advanced catalog and metadata capabilities with our Agentforce platform delivers exactly this.”
“Imagine an AI agent that goes beyond simply seeing data points to understanding their full context — origin, transformation, quality, and governance. This clarity, from a unified Salesforce and Informatica solution, will allow all types of businesses to automate more complex processes and make more reliable AI-driven decisions.”
Amit Walia.
Informatica CEO Amit Walia said: “Joining forces with Salesforce represents a significant leap forward in our journey to bring data and AI to life by empowering businesses with the transformative power of their most critical asset — their data. We have a shared vision for how we can help organizations harness the full value of their data in the AI era.”
Background
Informatica was founded by Gaurav Dhillon and Diaz Nesamoney in 1993. It went public on Nasdaq six years later and was subsequently acquired in 2015 by private equity house Permira and the Canada Pension Plan Investment Board for $5.3 billion. Microsoft and Salesforce Ventures participated in this deal, meaning Salesforce has had a close aquaintance with Informatica since then. Amit Walia was promoted to CEO in January 2020 from his role as President, Products and Marketing. Informatica then returned to public ownership with an NYSE listing in 2021.
Informatica stock price history chart.
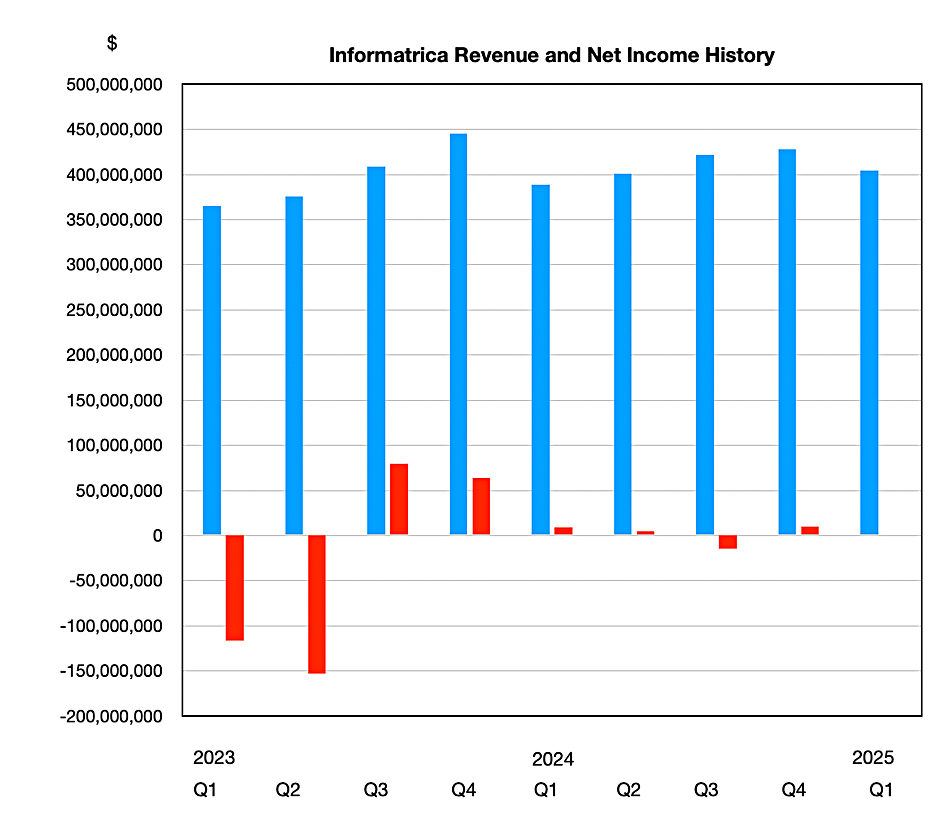
Eric Brown, Informatica’s CFO quit in early 2023 for other opportunities, when it laid off 7 percent of its headcount; around 450 employees. It bought data management tool supplier Privitar in mid 2023. Five months later, deciding to focus on its Intelligent Data Management Cloud (IDMC) business, it announced a restructuring plan, laying off 10 percent of its employees and cutting down on its real estate occupancy. A revenue history and profits chart shows the 2023 growth tailing off somewhat in 2024 with GAAP profits declining as well.
IDMC is a database/lake and cloud-agnostic product supporting AWS, Azure, Databricks, GoogleCloud, mongoDB, Oracle Cloud, Salesforce, Snowflake, and (Salesforce-owned) Tableau. Using its CLAIRE AI engine, it can ingest and aggregate structured and unstructured data from many different sources, with more than 70 source data connectors. Ingested data can be cleansed, classified, governed and validated. IDMC provides metadata management and a master data management service
Informatica integrated its AI-powered IDMC into Databricks’ Data Intelligence Platform in mid-2024. It announced a strengthened partnership with Databricks in January this year. At the end of the first 2025 quarter Informatica was a $1.7 billion annual recurring revenue business with more than 2,400 cloud subscription customers and 119 trillion cloud transactions per month, up from 200 billion/month in 2015.
Salesforce was rumoured to want to buy Informatica for less than its $11 billion market capitalisation in April last year and has now looks set to take over the business for $8 billion.
The transaction has been approved by the boards of directors of both companies and is expected to complete early in Salesforce’s fiscal year 2027, subject to the customary closing conditions. It will be funded through a combination of cash on Salesforce’s balance sheet and new debt.
When the deal completes, Salesforce will integrate Informatica’s technology stack — including data integration, quality, governance, and unified metadata for Agentforce, and a single data pipeline with MDM on Data Cloud — embedding this “system of understanding” into the Salesforce ecosystem.
Comment
Will other large suppliers with agentic AI strategies and a need for high-quality data aggregated from multifarious sources now be looking at getting their own data ingestion and management capabiities through acquisition? If so that would put Arcitecta, Datadobi, Data Dynamics, Diskover, Hammerspace and Komprise on a prospective purchase list.
PEAK:AIO claims it is solving AI inferencing model GPU memory limitations with CXL memory instead of offloading KVCache contents to NVMe flash drives.
The UK-based AI and GPU data infrastructure specialist says AI workloads are evolving “beyond static prompts into dynamic context streams, model creation pipelines, and long-running agents,” and the workloads are getting larger, stressing the limited high-bandwidth memory (HBM) capacity of GPUs and making the AI jobs memory-bound.
This causes a job’s working memory contents, its KVCache, to overflow HBM capacity, meaning tokens get evicted and have to be recomputed when needed again, lengthening job run-time. Various suppliers have tried to augment HBM capacity by having, in effect, an HBM memory partition on external flash storage, similar to a virtual memory swap space, including VAST Data with VUA, WEKA with its Augmented Memory Grid, and Pliops with its XDP LightningAI PCIe-add-in card front-ending NVMe SSDs.
PEAK:AIO is developing a 1RU token memory product using CXL memory, PCIe gen 5, NVMe and GPUDirect with RDMA.
Eyal Lemberger.
Eyal Lemberger, Chief AI Strategist and Co-Founder of PEAK:AIO, said in a statement: “Whether you are deploying agents that think across sessions or scaling toward million-token context windows, where memory demands can exceed 500GB per model, this appliance makes it possible by treating token history as memory, not storage. It is time for memory to scale like compute has.”
PEAK:AIO says its appliance enables:
KVCache reuse across sessions, models, and nodes
Context-window expansion for longer LLM history
GPU memory offload via CXL tiering
and Ultra-low latency access using RDMA over NVMe-oF
It claims that by harnessing CXL memory-class performance it delivers token memory that behaves like RAM, not files. The other suppliers listed: Pliops, VAST and WEKA, cannot do this. Mark Klarzynski, Co-Founder and Chief Strategy Officer at PEAK:AIO, said: “This is the token memory fabric modern AI has been waiting for.”
We’re told the tech gives AI workload developers the ability to build a system that can cache token history, attention maps, and streaming data at memory-class latency. PEAK:AIO says it “aligns directly with Nvidia’s KVCache reuse and memory reclaim models” and “provides plug-in support for teams building on TensorRT-LLM or Triton, accelerating inference with minimal integration effort.”
In theory PCIe gen 5 CXL controller latency can be around 200 nanoseconds while GPUDirect-accessed NVMe SSD access latency can be around 1.2ms (1,200,000ns); 6,000 times longer than a CXL memory access. Peak’s token memory appliance can provide up to 150 GB/sec sustained throughput at <5 microsecond latency.
Lemberger claimed: “While others are bending file systems to act like memory, we built infrastructure that behaves like memory, because that is what modern AI needs. At scale, it is not about saving files; it is about keeping every token accessible in microseconds. That is a memory problem, and we solved it [by] embracing the latest silicon layer.”
PEAK:AIO token memory appliance is software-defined, using off-the-self servers and is expected to enter production by the third quarter.
Comment: The big issue for storage suppliers is AI – how to store and make data accessible to AI agents and models. Here’s a look at how they are responding to this.
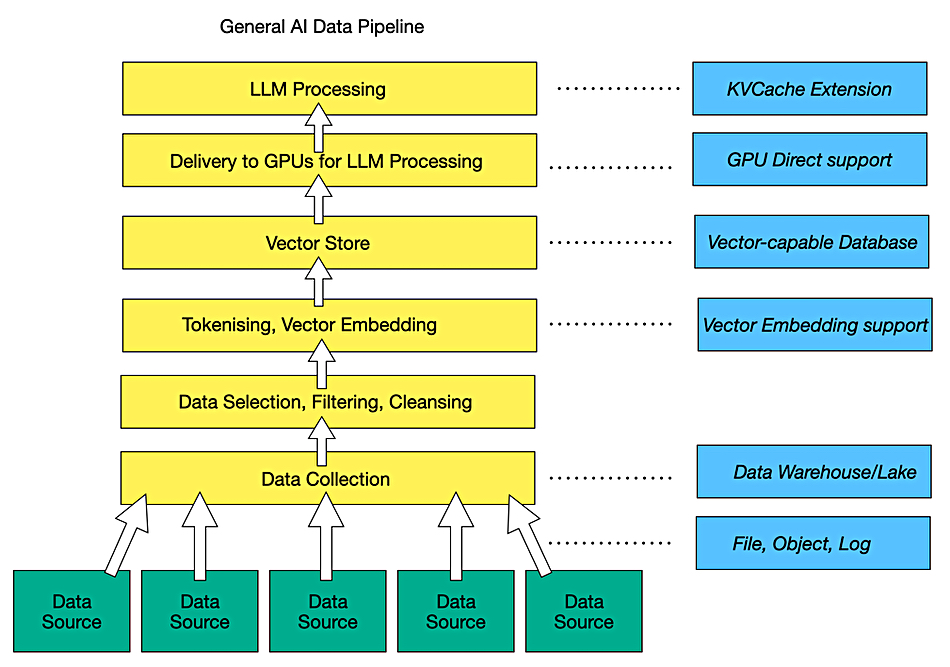
Using AI in storage management is virtually a no-brainer. It makes storage admins more effective and is becoming essential for cybersecurity. The key challenge is storing AI data so that it’s quickly accessible to models and upcoming agents through an AI data pipeline. Does a supplier of storage hardware or software make special arrangements for this or rely on standard block, file, and object access protocols running across Fibre Channel, Ethernet, and NVMe, with intermediate AI pipeline software selecting and sucking up data from their stores using these protocols?
There are degrees of special arrangements for base storage hardware and software suppliers, starting with the adoption of Nvidia GPUDirect support to send raw data to GPUs faster. This was originally limited to files but is now being extended to objects with S3 over RDMA. There is no equivalent to GPUDirect for other GPU or AI accelerator hardware suppliers. At each stage in the pipeline the raw data is progressively transformed into the final data set and format usable by the AI models, which means vector embeddings for the unstructured file and object data.
The data is still stored on disk or SSD drive hardware but the software managing that can change from storage array controller to data base or data lake and to a vector store, either independent or part of a data warehouse, data lake or lakehouse. All this can take place in a public cloud, such as AWS, Azure or GCP, in which case storage suppliers may not be involved. Let’s assume that we’re looking at the on-premises world or at the public cloud with a storage supplier’s software used there and not the native public cloud storage facilities. The data source may be a standard storage supplier’s repository or it may be some kind of streaming data source such as a log-generating system. The collected data lands on a storage supplier’s system or a data base, data lake or data lakehouse. And then it gets manipulated and transformed.
Before a generative AI large language model (LLM) can use unstructured data; file, object or log, it has to be identified, located, selected, and vectorized. The vectors then need to be stored, which can be in a specialized vector database, such as Milvus, Pinecone or Qdrant, or back in the database/lake/lakehouse. All this is in the middle and upper part of the AI pipeline, which takes in the collected raw data, pre-processes it, and delivers it to LLMs.
A base storage supplier can say they store raw data and ship it out using standard protocols – that’s it. This is Qumulo’s stance: no GPUDirect support, and AI – via its NeuralCache – used solely to enhance its own internal operations. (But Qumulo does say it can add GPUDirect support quickly if needed.) Virtually all enterprise-focused raw storage suppliers do support GPUDirect and then have varying amounts of AI pipeline support. VAST Data goes the whole hog and has produced its own AI pipeline with vector support in its database, real-time data ingest feeds to AI models, event handling, and AI agent building and deployment facilities. This is diametrically opposite to Qumulo’s stance. The other storage system suppliers are positioned at different places on the spectrum between the Qumulo and VAST Data extremes.
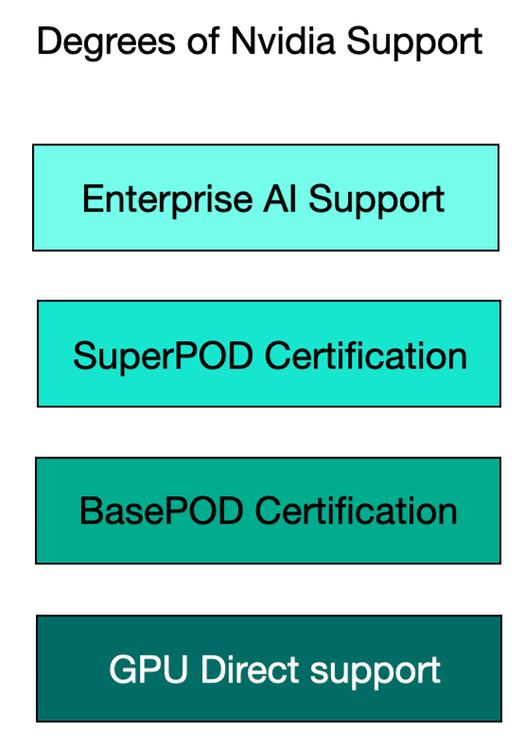
GPUDirect for files and objects is supported by Cloudian, Dell, DDN, Hammerspace, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Pure Storage, Scality, and VAST. The support is not necessarily uniform across all the file and object storage product lines of a multi-product supplier, such as Dell or HPE.
A step up from GPUDirect support is certification for Nvidia’s BasePOD and SuperPOD GPU server systems. Suppliers such as Dell, DDN, Hitachi Vantara, HPE, Huawei, IBM, NetApp, Pure Storage, and VAST have such certifications. Smaller suppliers such as Infinidat, Nexsan, StorONE, and others currently do not hold such certifications.
A step up from that is integration with Nvidia Enterprise AI software with its NIM and NeMo retriever microservices, Llama Nemotron model, and NIXL routines. Dell, DDN, Hitachi Vantara, HPE, NetApp, Pure, and VAST do this.
Another step up from this is to provide a whole data prep and transformation, AI model support, agent development and agentic environment, such as what VAST is doing with its AI OS, with Dell, Hitachi Vantara and HPE positioned to make progress in that direction via partners, with their AI factory developments. No other suppliers appear able to do this as they are missing key components of AI stack infrastructure, which VAST has built and which Dell, Hitachi Vantara and HPE could conceivably develop, at least in part. From a storage industry standpoint, VAST is an outlier in this regard. Whether it will remain alone or eventually attract followers is yet to be answered.
This is all very Nvidia-centric. The three main public clouds have their own accelerators and will ensure fast data access by these to their own storage instances, such as Amazon’s S3 Express API. They all have Nvidia GPUs and know about GPUDirect and should surely be looking to replicate its data access efficiency for their own accelerators.
Moving to a different GPU accommodation tactic might mean looking at KV cache. When an AI model is being executed in a GPU, it stores its tokens and vectors as keys and values in the GPU’s high-bandwidth memory (HBM). This key-value cache is limited in capacity. When it is full and fresh tokens and vectors are being processed, old ones are over-written and, if needed, have to be recomputed, lengthening the model’s response time. Storing evicted KV cache contents in direct-attached storage on the GPU server (tier 0), or in networked, RDMA-accessible external storage (tier 1), means they can be retrieved when needed, shortening the model’s run time.
Such offloading of the Nvidia GPU server’s KV cache is supported by Hammerspace, VAST Data, and WEKA, three parallel file system service suppliers. This seems to be a technique that could be supported by all the other GPUDirect-supporting suppliers. Again, it is Nvidia-specific and this reinforces Nvidia’s position as the overwhelmingly dominant AI model processing hardware and system software supplier.
The cloud file services suppliers – CTERA, Egnyte, Nasuni, and Panzura – all face the need to support AI inference with their data and that means feeding it to edge or central GPU-capable systems with AI data pipelines. Will they support GPUDirect? Will Nvidia develop edge enterprise AI inference software frameworks for them?
The data management and orchestration suppliers such as Arcitecta, Datadobi, Data Dynamics, Diskover, Hammerspace, and Komprise are all getting involved in AI data pipeline work, as selecting, filtering, and moving data is a core competency for them. We haven’t yet seen them partnering with or getting certified by Nvidia as stored data sources for its GPUs. Apart from Hammerspace, they appear to be a sideshow from Nvidia’s point of view, like the cloud file services suppliers.
Returning to the mainstream storage suppliers, all of the accommodations noted above apply to data stored in the supplier’s own storage, but there is also backup data, with access controlled by the backup supplier, and archival data, with access controlled by its supplier. We have written previously about there being three separate AI data pipelines and the logical need for a single pipeline, with backup suppliers positioned well to supply it.
We don’t think storage system suppliers can do much about this. There are numerous backup suppliers and they won’t willingly grant API access to their customer’s data in their backup stores.
If we imagine a large distributed organization, with multiple storage system suppliers, some public cloud storage, some cloud file services systems, some data protection suppliers, an archival vault, and some data management systems as well, then developing a strategy to make all its stored information available to AI models and agents will be exceedingly difficult. We could see such organizations slim down their storage supplier roster to escape from such a trap.
Lenovo reported its second-ever highest revenues for the fourth fiscal 2025 quarter as unexpected tariff rises affected profitability.
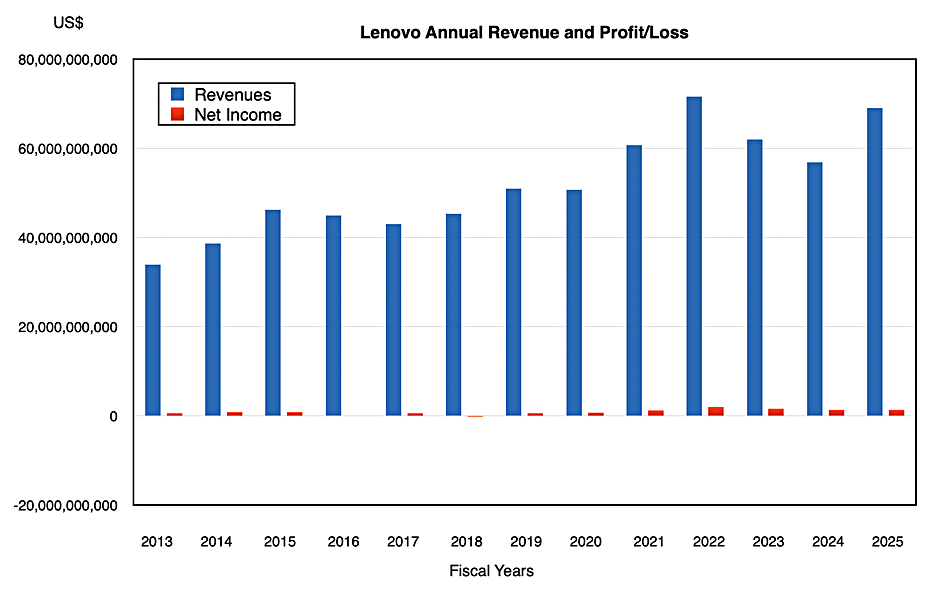
Revenues in the quarter, ended March 31, were up 23 percent Y/Y to $17 billion, with GAAP net income of $90 million, down 64 percent from the year-ago $248 million.
Full fy2025 revenues were 21 percent higher at $69.1 billion, its second ever highest amount, with GAAP net income of $1.4 billion, up 36 percent and representing just 2 percent of revenues. Dell earned $95.6 billion in revenues in its fiscal 2025 with 4.8 percent of that as profit; $4.6 billion. Lenovo could be viewed as similar to Dell but without its strong storage hardware and software revenues. The Infrastructure Solutions Group(ISG) in Lenovo experienced hyper-growth with with revenue up 63 percent Y/Y to a record $14.5 billion
Yuanqing Yang
Yuanqing Yang, Lenovo’s Chairman and CEO, stated: “This has been one of our best years yet, even in the face of significant macroeconomic uncertainty. We achieved strong top-line growth with all our business groups and sales geographies growing by double digits, and our bottom-line increased even faster. Our strategy to focus on hybrid AI has driven meaningful progress in both personal and enterprise AI, laying a strong foundation for leadership in this AI era.”
He thought it was “particularly remarkable that we achieved such results amid a volatile and challenging geopolitical landscape and the industry environment.”
Yang finished his results presentation with a particularly Chinese sentiment: “No matter what the future may hold, remember, while the tides answer to forces beyond us, how we sail the ship is always our decision.” Very true. If he was playing the Bridge card game he would prefer to make no trumps bids.
Lenovo experienced an unexpected and strong impact from tariffs and that, we understand, contributed to its profits decline in the quarter. Yang said tariff uncertainty was a bigger worry than tariffs themselves, as Lenovo, with its distributed manufacturing base, can adjust production once it knows what tariffs are and has a stable period in which to make changes. But President Trump’s tariff announcements are anything but stable.
Lenovo has three business units, Intelligent Devices Group (IDG) focusing on PCs, Infrastructure Solutions Group (ISG) meaning servers and storage, and SSG, the Solutions and Services Group.
It said IDG, Lenovo’s largest business unit by far, “enlarged its PC market leadership” in the quarter, gaining a percentage point of market share over second-placed Dell. IDG quarterly revenues grew 13 percent. ISG “achieved profitability for the 2nd consecutive quarter, with revenue hypergrowth of more than 60 percent year-on-year.” SSG delivered 18 percent revenue growth year-on year.
Yang said that, with ISG: “We have successfully built our cloud service provider or CSP business into a scale of USD 10 billion and self sustained profitability. Meanwhile, our traditional Enterprise SMB business also gained strong momentum with 20 per cent year-on-year growth, driving the revenue to a record high.”
The Infinidat business, when that acquisition completes, will enable Lenovo to enter the mid-to-upper enterprise storage market. CFO Winston Cheng indirectly referred to this in a comment:”Going forward, ISG will continue to focus on increasing volume and profitability for its E/SMB business through its streamlined portfolio, enhanced channel capabilities and high-value 3S offerings across storage, software and services.”
New ISG head Ashley Gorakhpurwalla answered a question in the earnings call about ISG’s Enterprise/SMB business: “A very new and refreshed set of compute and storage products from Lenovo offer all of our enterprise and small, medium customers a very rapid return on investment during their technology refresh cycles. So we believe firmly that we are on track for continued momentum in this space and improved profitability in the enterprise infrastructure.”
Lenovo said all its main businesses saw double-digit revenue growth in fy2025. It made significant progress in personal and enterprise AI, noting: “The AI server business … achieved hypergrowth thanks to the rising demand for AI infrastructure, with Lenovo’s industry-leading Neptune liquid cooling solutions as a key force behind this rapid growth.”
The company referred to hybrid AI fueling its performance, meaning AI that integrates personal, enterprise and public data.
It is increasing its R&D budget, up 13 percent Y/Y to $2.3 billion, and said it made an AI super agent breakthrough in the quarter, referring to its Tianxi personal agent, which it claims can handle intricate commands across various platforms and operating systems.