


Chinese computer scientists reckon they have found a way to get through a metadata access bottleneck slowing file access when you’re looking for that one file in 100 billion.
Filesystems all store files inside a file and folder structure giving users control over where files are stored. This is in contrast to a database where a record is added and the database decides where it goes based on the record type and contents. If then a user needs to search for the record then some search language like SQL, is needed. Eg; SELECT * FROM Fruits WHERE Fruit_Color=‘Red’.
It’s different with files as you can just tell an OS or application to open a named file, and the system will happily tell you what files exist and where:
I can use this file-folder listing to tell the system to open file INfiniFS.pdf and it will then go to the right drive location (block address) and get it for me. Simple. But this is just my Mac PC and there are only a few thousand files in total on it, of which only a thousand or so, spread across tens of folders and sub-folders, are of interest to me, the rest being system files. A disk or flash drive is like a house, with folders being equivalent to rooms, sub-files stored in shelving units, and files stored on shelves in the units. It’s easy to enter the house, walk to the right room, find the right shelving unit and then the correct shelf.
The drive name and file access navigation path through the drive/folder/sub-folder structure are metadata items; special data describing where and how to access the actual content (inside a file) that I want.
But when the PC is actually a cluster of servers with millions of files, this metadata becomes extremely large and more so when you consider the file system software will check if you have permission to read or separately write to a file.
The 100-billion-file problem
Now let’s imagine the situation when there are thousands of servers and up to 100 billion files. It is now a distributed filesystem and the file location task is immensely difficult. The metadata is being checked constantly as users or applications read files, write to files, delete files, create new ones, and move groups of files from one sub-folder to another.
There have to be specific metadata servers, dedicated to just one metadata processing job, and they operate in a coordinated fashion within a single file namespace. The metadata processing burden has to be load-balanced across these servers so that file access bottlenecks can be prevented from slowing things down.
But that means my file access request may have to hop from one metadata server to another; it’s no longer local to one server, and the access takes more time to process. Access paths can become long, with 10, 11, 12 or more nested folders to navigate, and the top-level section of the file:folder structure, the drive and top level directories, could become processing hotspots, further delaying access as queues build up.
Five Chinese researchers devised InfiniFS to solve these three issues. Their scientific paper, “InfiniFS: An Efficient Metadata Service for Large-Scale Distributed Filesystems”, states in its abstract: “Modern datacenters prefer one single filesystem instance that spans the entire datacenter and supports billions of files. The maintenance of filesystem metadata in such scenarios faces unique challenges, including load balancing while preserving locality, long path resolution, and near-root hotspots.”
Three-way fix
Their InfiniFS scheme has three pillars:
- It decouples the access and content metadata of directories so that the directory tree can be partitioned with both metadata locality and load balancing.
- InifiniFS has speculative path resolution to traverse possible file access paths in parallel, which substantially reduces the latency of metadata operations.
- It has an optimistic access metadata cache on the client side to alleviate the near-root hotspot problem, which effectively improves the throughput of metadata operations.
An architectural diagram from the paper illustrates these three notions:
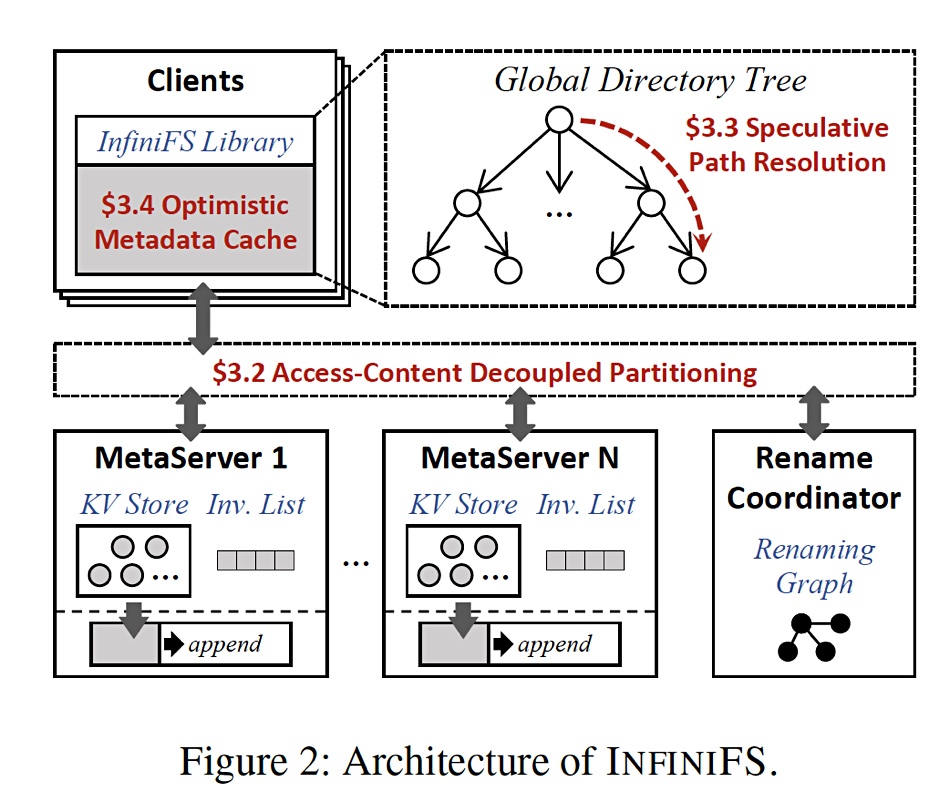
The key idea of the access and content metadata separation “is to decouple the access metadata (name, ID, and permissions) and content metadata (entry list and timestamps) of the directory, and further partition these metadata objects at a fine-grained level.”
InfiniFS stores metadata objects as key-value pairs:

Generally high-content file systems treat the directory metadata as a whole. When partitioning the directory tree – dividing it between different metadata servers – they have to split the directory either from its parent or its children to different servers, which unintentionally breaks the locality of related metadata. The InfiniFS access and content decoupling function aims to fix this problem: “We group related metadata objects to the same metadata server to achieve high locality for the metadata processing phase.”
Another diagram depicts the decoupling concepts and is worth studying carefully to appreciate a file and directory metadata split and the access and content metadata separation (access, half-filled red circles, and content, half-filled blue circles):
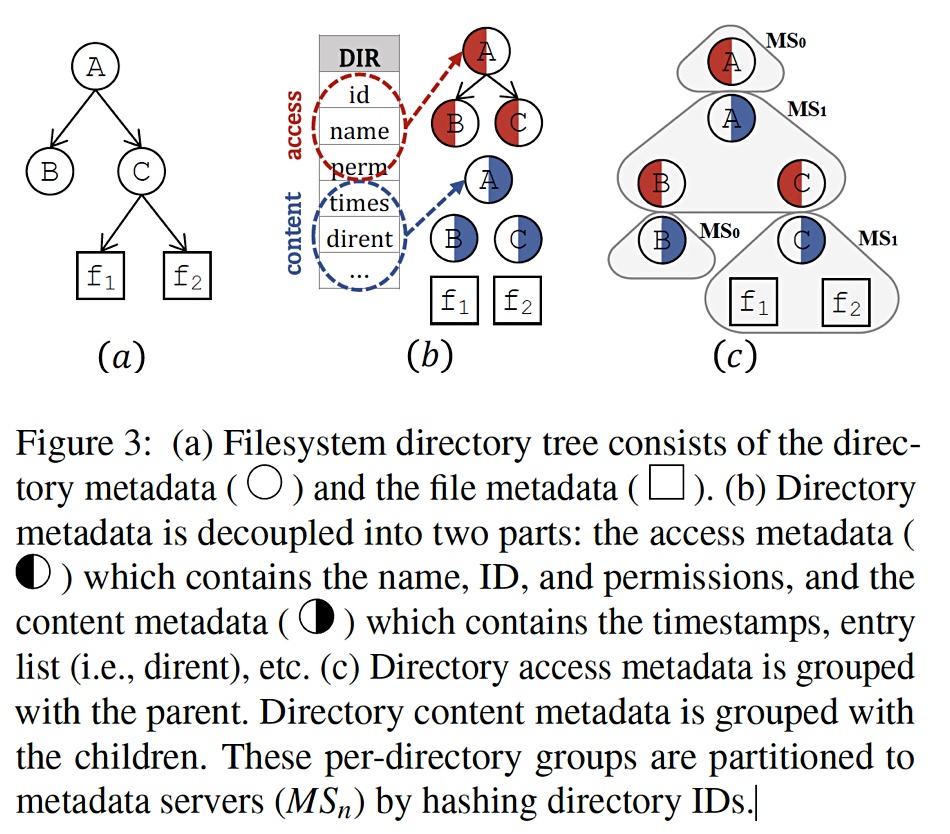
The idea is to enable searches of a directory tree sub-structure (per-directory groups) that can be done inside a single metadata server and avoid hops to other metadata servers.
For the speculative path resolution, “InfiniFS uses a predictable ID for each directory based on the cryptographic hash on the parent ID, the name, and a version number. It enables clients to speculate on directory IDs and launch lookups for multi-component paths in parallel.” The researchers add: “Speculative path resolution (S-PR) reduces the latency of path resolution to nearly one network round-trip time, if correctly predicted.”
With regard to the caching: “Cache hits will eliminate lookup requests to near root directories, thereby avoiding hotspots near the root and ensuring scalable path resolution.”
Performance
The researchers compared InfiniFS metadata processing performance time with LocoFS, IndexFS, HopsFS, and CephFS, using a RAM disk to avoid drive IO speed differences. InfiniFS had higher throughput and lower latency:
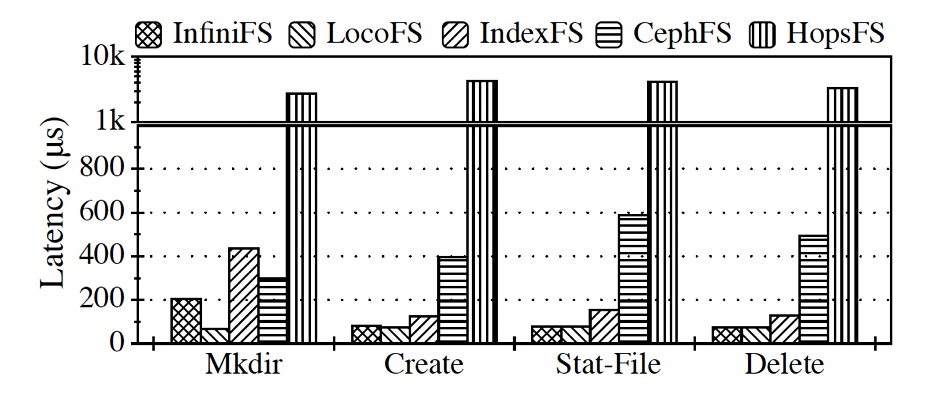
The researchers conclude: “The extensive evaluation shows that InfiniFS provides high-performance metadata operations for large-scale filesystem directory trees.”
This is a 17-page paper and we have only provided a bare overview here. The paper is free to download and may suggest ways that, for example, Ceph could be improved to match filesystems with better performance, such as Qumulo Core and WEKA’s Matrix.





