


MemVerge’s DRAM virtualizing Memory Machine software can use CXL to give GPUs more memory and rescue them from being stranded waiting for memory loading.
Update: GDDR6 is not HBM and MemVerge/FlexGen is managing GPU, CPU and CXL memory modules. 18 March 2024.
CXL v3.0 can pool external memory and share it with processors via CXL switches and coherent caches. MemVerge’s software virtually combines a CPU’s memory with a CXL-accessed external memory tier and is being demonstrated at Nvidia’s GTC event. Micron and MemVerge report they are “boosting the performance of large language models (LLMs) by offloading from GPU HBM to CXL memory.”

MemVerge co-founder and CEO Charles Fan said in an issued statement: “Scaling LLM performance cost-effectively means keeping the GPUs fed with data. Our demo at GTC demonstrates that pools of tiered memory not only drive performance higher but also maximize the utilization of precious GPU resources.”
The MemVerge and Micron engineer-led demo features a FlexGen high-throughput generation engine and OPT-66B large language model running on a Supermicro Petascale Server. This is fitted with an AMD Genoa CPU and 384 MB of DRAM, Nvidia A10 GPU, Micron DDR5-4800 DIMMs, CZ120 CXL memory modules, and MemVerge Memory Machine X intelligent tiering software.
It contrasts running the job in an A10 GPU with 24GB of GDDR6 memory, and fed data from 8x 32GB Micron DRAM vs running it in the same configuration Supermicro server fitted with Micron CZ120 CXL 24GB memory expander and the MemVerge software.
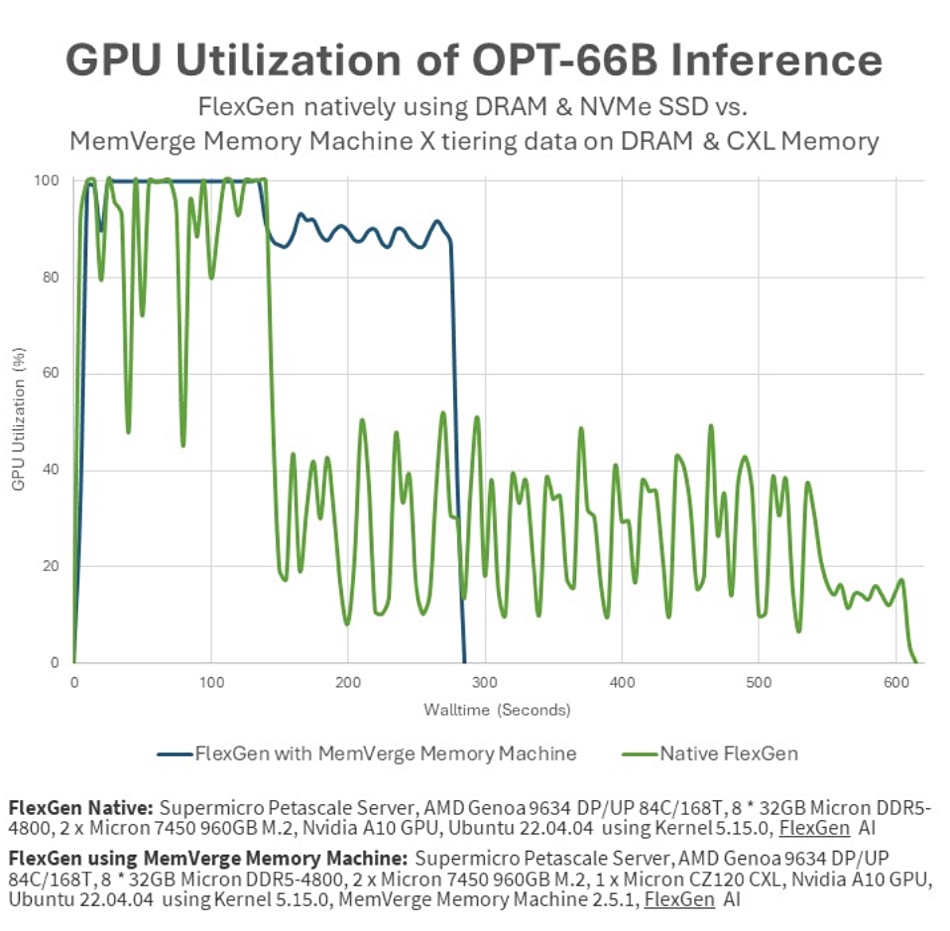
The FlexGen job, with transparent tiering from DRAM DIMMS to CXL-boosted memory, runs more than twice as fast – blue line on chart above – with 77 percent better GPU utilization. There is zero NVMe SSD I/O and three times more tokens/sec processed when CXL tiering is used. The GPU runs at 51.8 percent utilization without CXL memory and this jumps to to 91.8 percent with the Memory Machine X software and CXL memory.
As we understand from an Nvidia A10 datasheet this GPU has 24GB of GDDR6 memory, which is not generally reckoned to be high-bandwidth memory (HBM). Our understanding is that the Micron CXL expander memory is pooled with the AMD processor’s memory and not with the A10 GPU’s GDDR6 DRAM. We are checking these two specific points with MemVerge as they affect the HBM offloading claim. A MemVerge spokesperson said: “[The] A10 uses GDDR6 memory instead of HBM. Our solution does have the same effect on the other GPUs with HBM. He also told us: “Between Flexgen’s memory offloading capabilities and Memory Machine X’s memory tiering capabilities, the solution is managing the entire memory hierarchy that includes GPU, CPU and CXL memory modules.”
Raj Narasimhan, SVP and GM of Micron’s Compute and Networking Business Unit, declared: “Through our collaboration with MemVerge, Micron is able to demonstrate the substantial benefits of CXL memory modules to improve effective GPU throughput for AI applications resulting in faster time to insights for customers.”
Attendees at Nvidia GTC can see the MemVerge demo of FlexGen acceleration at the Micron booth, number 1030.





