


Aparavi has announced the availability of new connectors to bring its data management tools to SharePoint Server and OneDrive – the sales pitch being that it is helping organizations reduce costs, increase efficiency and reduce risk by analyzing and optimizing unstructured data. The Aparavi Platform is intended to provide a deep dive into data and metadata in SharePoint and OneDrive to identify redundant files, aging files, files with sensitive information, and more. It scans and finds unstructured data based on hundreds of criteria and can automate chores such as classifying, deleting, and moving data to offsite archive to reduce storage footprints. It can locate redundant, obsolete, and trivial (ROT) data – typically 25-80 percent of business files – to free up storage. It can also identify files with regulated personal information such as SSNs or financial information, and confidential business data, that might be vulnerable to data breaches and cyberattacks.
…
Unified analytics platform supplier CelerData has announced the latest version of its enterprise analytics platform, CelerData v3, which we’re told gives lakehouse users the option to conduct high-performance analytics without ingesting data into a central data warehouse. Compared to other common query engines, CelerData improves query performance by at least 3 times while significantly reducing infrastructure cost. It is built on top of the open source project StarRocks, the fastest MPP SQL database – recently donated to the Linux Foundation.
Data lakehouse users can perform analytics by querying across streaming data and historical data in real-time, without having to wait and combine streaming data into batches for analysis, CelerData says. This is designed to simplify the data architecture and improve the timeliness of lakehouse analytics. CelerData’s query engine can support thousands of concurrent users at 10,000 QPS (Queries Per Second), enabling use cases previously not possible on the data lakehouse, the company says.
…
Cloud file services business Nasuni says Enterprise IT continues to rapidly move file data infrastructure to the cloud, which along with the serious threat of ransomware and the need to support hybrid and remote work, has fuelled strong demand for the Nasuni File Data Platform with Azure Blob Storage. It’s “achieved a major milestone, with more than 500 customers using Nasuni to access and protect upwards of 100 petabytes (PB) of primary customer file data workloads residing in Microsoft Azure.” The expansion of Nasuni users leveraging Azure has been strong since 2019, with a compound annual growth rate (CAGR) of 74 percent and a 66 percent increase in the number of joint customers. In fact, the amount of data going into Azure from Nasuni users is accelerating relative to past years — the company’s customers added an average of 3 PB per month into Azure throughout 2022.
…
Cybersecurity company NordVPN has launched a new free model, giving consumers the security of a Virtual Private Network (VPN) when sharing files. The Meshnet feature, now available without a subscription, allows users to access other devices, wherever they are in the world. The service acts like a local area network (LAN), connecting devices directly and enabling instant and safe file sharing. Meshnet creates a peer-to-peer link between computers or mobile devices, secured by an encrypted VPN tunnel.
…
SSD controller company Phison announced the launch of IMAGIN+, an upgraded platform offering R&D resource sharing and ASIC (Application-Specific Integrated Circuit) design services for NAND flash controllers, storage solutions, PMIC, and Redrivers/Retimers. The introduction of IMAGIN+ came during the Embedded World Exhibition & Conference (March 14-16) in Nuremberg.
…
Jerome Lecat , CEO at object – and file – storage supplier Scality, said in a LinkedIn post that Scality achieved profitability in the second half of 2022. He wrote: “we want to leverage on the new interest for Object Storage, especially for backup, and build on the flexibility of our RING software and the simplicity of ARTESCA. ARTESCA has seen its pipeline multiplied by 10x in 12 months as we enable VARs to demonstrate, sell, install and operate it.”
…
Sycomp has confirmed that Sycomp Storage Fueled by IBM Spectrum Scale is now available in the Google Marketplace. It enables you to simultaneously access data from hundreds of virtual machines. Dean Hildebrand, Technical Director, Office of the CTO at Google. “Sycomp Storage Fueled by IBM Spectrum Scale provides a performant parallel file system that can dynamically access data in Google Cloud Storage and then deliver up to 320 GB/s (NFS) of low latency read capability.” It automatically manages tiers of storage to ensure maximum performance and reduce cost.
…
We came across a VAST Data white paper comparing file system products from VAST, IBM, Dell and Pure Storage. A table in it has been reproduced for a quick look at VAST’s picture of its competition;
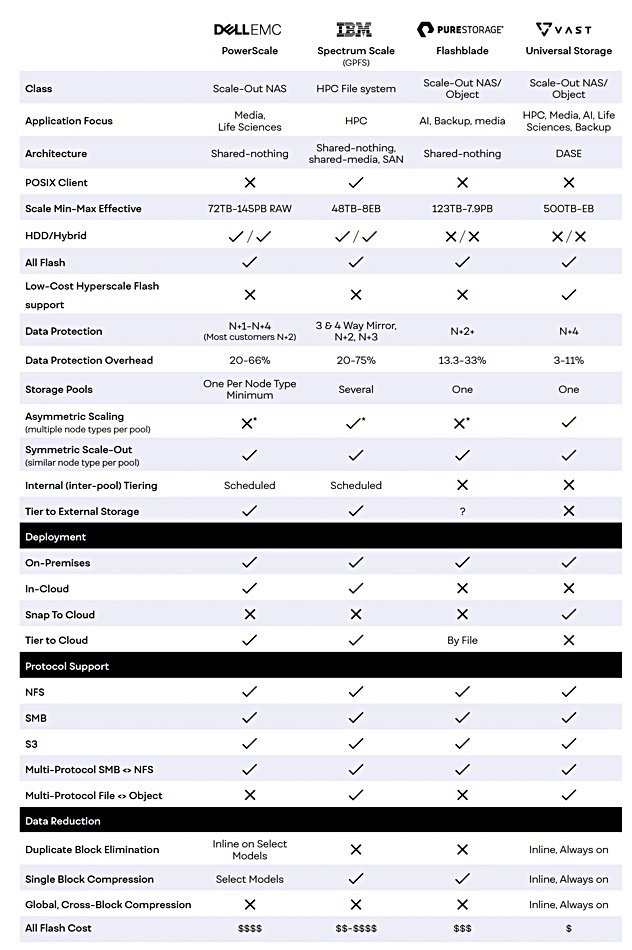
…
Privately-owned VAST Data is trumpeting its success in 2022, claiming it had record-breaking growth to $100 million in annual recurring revenue, up from $1 million in 2020 – the fastest business to reach that milestone in the data infrastructure industry. It reckons it was cash-flow-positive for the third successive year. It quadrupled the number of Fortune 1000 customers, with its top one hundred new customers spending more than $1.2 million on average. VAST’s headcount has passed the 500 mark and it closed the year with more than eight exabytes of licensed capacity under management.
…
Wikibon analyst David Vellante has written a paper saying lakehouse supplier Databricks faces critical decisions. It says “the trend is toward a common repository for analytic data. That might be multiple virtual warehouses inside of a Snowflake account or Lakehouses from Databricks or multiple data lakes in various public clouds with data integration services that allow developers to integrate data from multiple sources. … In the relatively near future, we believe customers will be managing hundreds or thousands or more data connections. Today’s systems can maybe handle 6-8 joins in a timely manner, and that is the fundamental problem. Our premise is that a new big data era is coming and existing systems won’t be able to handle it without an overhaul.”

The conclusion is that Databricks has to keep maintaining what its done in the old world, but has to build something new that’s optimized for the new world. It’s a case of digital joinery.





