


We are seeing more and more announcements about data pipelines and the need to go beyond Extract, Transform and Load (ETL) procedures that are specific to a single analysis application or data warehouse. The concept of general purpose and extensible data pipelines is taking shape with suppliers such as Airbyte, Arcion and Delphix.
Arcion is developing a cloud-native, change data capture-based data replication platform. It was founded in 2016 and, after arranging a 2020 convertible note, has taken in $18.2 million via a 2021 $5.2 million pre-seed round, and a February 2022 $13 million A-round.
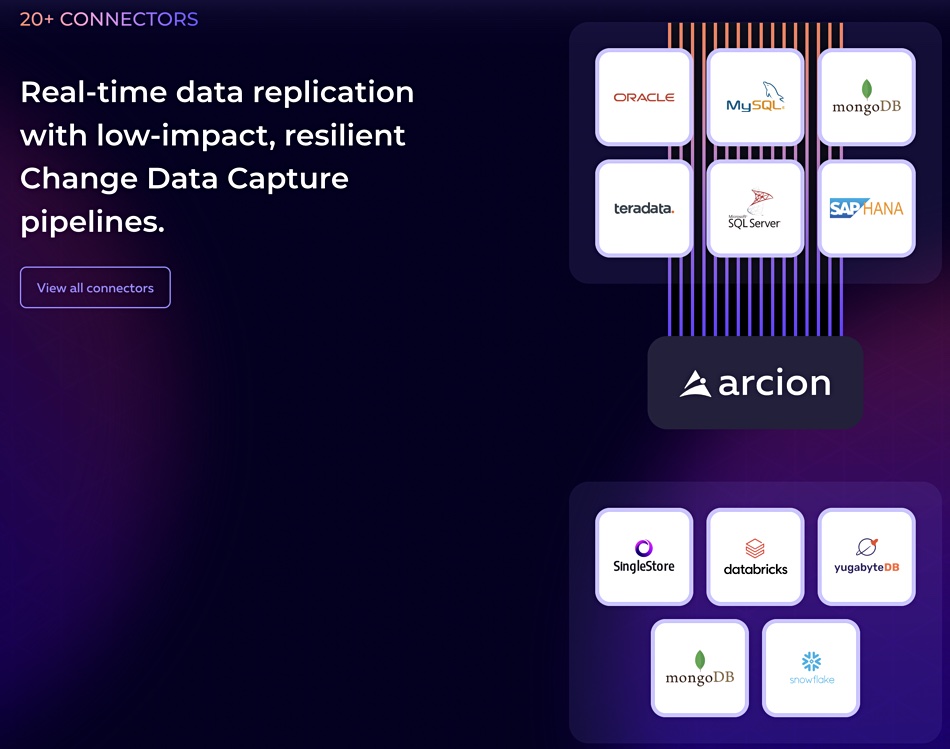
Arcion Cloud enables you to create data pipelines connecting data sources to data targets; Oracle to SingleStore, for example. It has a library of more than 20 connectors that provide native support for enterprise databases, data warehouses, and cloud analytics platforms, such as Imply, Greenplum, DB2, SAP IQ, Snowflake, and Amazon Aurora. Partners include Databricks, SingleStore, Snowflake, and Yugabyte.

We talked to Arcion founder and chief technology officer Rajkumar Sen about his data pipeline ideas.
In Sen’s previous role as director of engineering at MemSQL (now SingleStore), he architected the query optimizer and the distributed query processing engine. He also served as a principal engineer at Oracle, where he developed features for the Oracle database query optimizer, and as a senior staff engineer at Sybase, where he architected several components for the Sybase Database Cluster Edition.
He has published over a dozen papers in top-tier database conferences and journals and is the recipient of 14 patents. In other words, he knows his stuff.
Blocks & Files: Could you introduce your views of data pipelines?
Rajkumar Sen: Data is the most valuable asset for modern businesses. For any organization to extract valuable insights from data, that data needs to flow freely in a secure and timely manner across its different platforms (which are producing and consuming the data). Data pipelines that connect these sources and targets need to be carefully designed and implemented, else data consumers may be frustrated with data that is either old (refreshed several days back) or simply incorrect (mismatched across source and target). That could lead to bad or inaccurate business decisions, slower insights, and lost competitive advantage.
Blocks & Files: Where is the data located?
Rajkumar Sen: The business data in a modern enterprise is spread across various platforms and formats. Data could belong to an operational database (e.g., Mongo, Oracle, etc.), cloud warehouses (e.g., Snowflake), data lakes and lakehouses (e.g., Databricks Delta Lake), or even external public sources. Data pipelines connecting this variety of sources need to establish some best practices so that data consumers get high-quality data delivered to where their data apps are being built.
Blocks & Files: What are the best data pipeline practices you would recommend?
Rajkumar Sen: Some of the best practices that a data pipeline process can follow are:
- Make sure that the data is delivered reliably and with high integrity and quality. The concept of “garbage in, garbage out” applies here. Data validation and correction is an important aspect of ensuring that.
- Ensure that the data transport is highly secure and no data is in stable storage unencrypted.
- The data pipeline architecture needs to be flexible and able to adapt to a business’s future growth trajectory. An addition of a new data source should not lead to rewrite of the pipeline architecture. It should merely be an add-on. Otherwise, it will be very taxing on the data team’s productivity.
Blocks & Files: Can customers do it themselves and set up their own pipelines?
Rajkumar Sen: A frequent mistake that data teams make is to underestimate the complexity of data pipelines. A DIY approach only makes sense if the data engineering team is large and capable enough to deal with the complexities of high-volume, high-velocity, and variety of the data. It would be wise to first evaluate if using a data pipeline platform would suffice the needs before rushing to implement something in-house. There are several platforms available in the market today in the ETL/ELT/reverse ETL space: Arcion, Fivetran, Matillion, Airbyte, Meroxa, Census and Hightouch, among others.
Blocks & Files: Are there other pitfalls that lie in wait for DIY businesses?
Rajkumar Sen: Another pitfall is to implement a vertical solution that caters to only the first use case instead of architecting a solution that would be flexible enough to add new sources and targets without a complete rewrite. Data architects should think holistically and design solutions that are flexible and can work with a variety of data sources (relational, unstructured, etc.).
The third mistake data pipeline creators often make is to avoid any sort of data validation until a data mismatch occurs. When a mismatch occurs, it is already too late to implement any form of data validation or verification. Data validation should be a design goal of any data pipeline process from the very outset.





