


Kalista IO’s Phalanx software separates read from write SMR disks in a JBOD to bring big performance gains to server applications which need no code changes, not even for host-managed SMR.
If the foregoing is gobbledegook, then stick with me as I bring a little light to the darkness, learnt at an IT Press Tour briefing. It’ll be worth it.
SMR or Shingled Magnetic Recording disk drives have a 17 per cent or so capacity increase over equivalent technology conventionally-recorded (CMR) drives. Thus a 16TB conventional drive could be an 18.7TB SMR drive with only a software change in the disk controller. SMR works by taking advantage of read tracks being narrower than write tracks – a quirk of HDD technology – and partially overlaps write tracks to leave the read tracks closer together. This enables more of them to exist on a disk platter, thus upping the capacity.
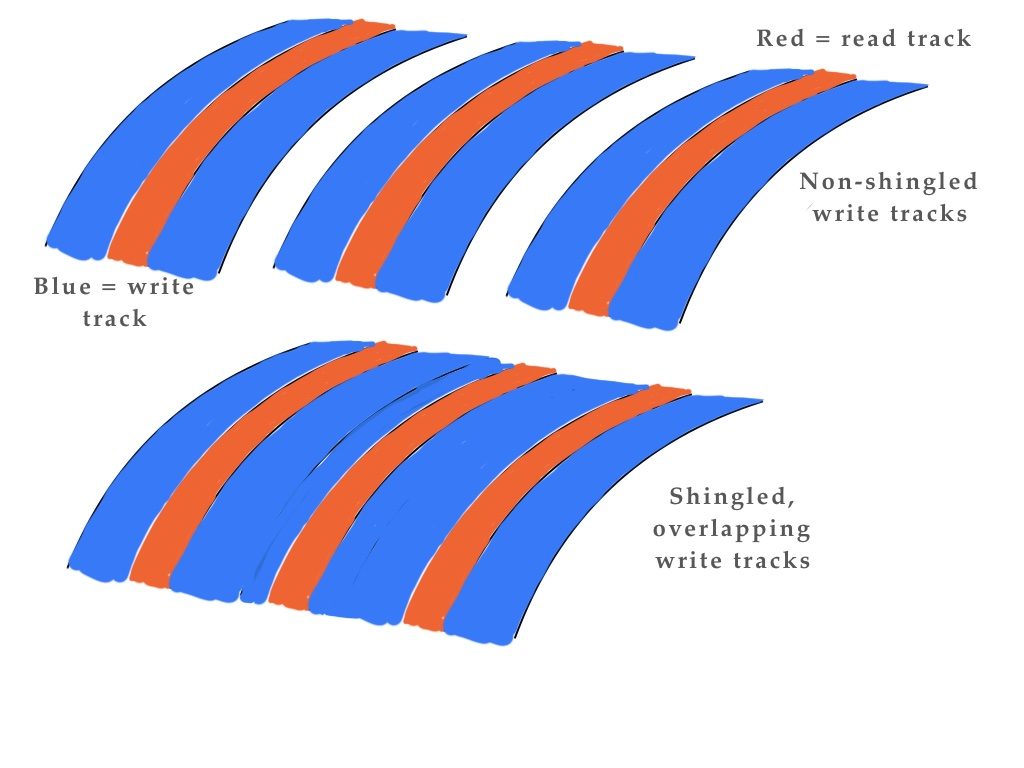
The downside – and it’s a significant one – is that when data has to be rewritten, a whole block or zone of SMR tracks has to be read, the new data inserted, and then the block written back to the disk. This makes adding data to existing blocks slower than with conventional drives, and entails application or host server system software changes if the server host manages the SMR process (host-managed SMR). These disadvantages have seriously slowed SMR drive adoption, even though a 17 per cent capacity jump would be attractive to any user with tens, hundreds, or thousands of disk drives.
Albert Chen was an engineering program director at Western Digital and spent six and a half years working on its SMR drive technology. He then went to stealth startup Rstor for two years as a senior director working on the the development of an S3-compatible object store.
He realised that there was a fundamental problem with disk drives: the single head per platter has to do both reads and writes and these actions could be random or sequential.
There is contention between reads and writes for the head. SMR performance sucks when sequential data is being re-written in a block and really sucks when random data is being rewritten across blocks. If you had a fleet of disk drives in, say, a hundred-drive JBOD, then you could separate read and write activity and have them take place on different drives, so there was no head contention.
Phalanx scheme
But you could do something really significant on SMR drives. All data to be written would be written sequentially and appended to the existing data. There is no rewriting over existing data as with the existing SMR scheme. Reads would take place on previously written drives. A diagram shows the concept:
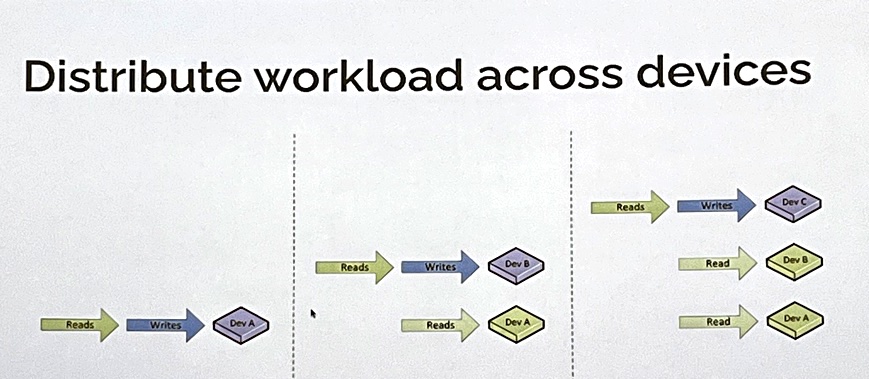
You both read and write on the first disk in the fleet. When it’s full you write to the second disk and only read from the first disk. When the second disk is full you move to writing on the third disk and only read from the second disk. Rinse and repeat. Any data deleted is marked deleted in the Phalanx HDD metadata store on the host but not actually overwritten. With a fleet of drives you can have multiple writers and multiple readers, increasing capacity and concurrency as disks are added, performance and reducing contention:

As data gets deleted older disks become fragmented and the defrag process is to copy their data to a spare drive in the background, mark the source disk as empty and return it to the write pool for re-use.
So you don’t reclaim deleted capacity straight away, but you do gain performance. In fact, in some circumstances a box of Phalanx-controlled SMR drives can outperform the same box filled with conventional HDDs. For example, on a Mongo DB run the percentage difference between Phalanx-controlled SMR drives and conventional HDDs looked like this:

Some things were slightly slower and some slightly faster.
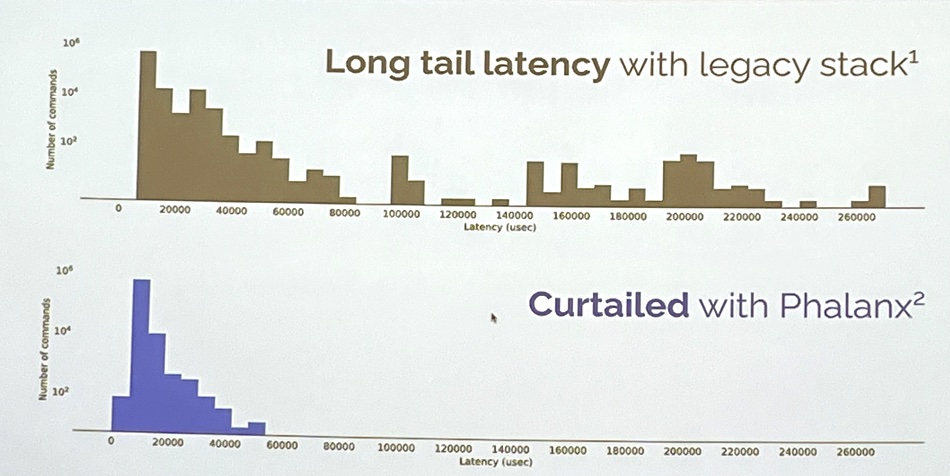
Phalanx can seriously decrease long tail latency:
It is use case-dependent. On a MinIO run it increased average write IOPS by 60 per cent and read IOPS by 35 per cent.
Phalanx is, in effect, a host-resident software JBOD controller, similar to a storage array controller. It supports file, blocks and object interfaces and you can mix and match disk drives in a Phalanx fleet.
Its use can expand the use case possibilities for SMR drives significantly:

Who should be interested in looking at Phalanx and checking it out?
- Any hyperscaler operation with significant HDD populations in the tens of thousands, such as AWS, Azure, GCP, Facebook, Twitter, etc.
- Any sub-hyperscaler with thousands of drives, such as Backblaze (hi Gleb Budman), Datto and Wasabi.
- Any enterprise with hundreds to thousands of drives.
- Any disk-based storage supplier with tens to hundreds of drives in its arrays – hi Infinidat and Phil Bullinger especially, Dell EMC, HPE, NetApp, DDN and others like the object storage suppliers.
- Any disk drive manufacturer making SMR drives and also selling JBODs such as Toshiba’s KumoScale and Seagate’s Exos 4U106.
Kalista IO’s Phalanx could be the rescue party needed for SMR drives and JBODs.





