


Versity Software, an archive software company, has open sourced ScoutFS, a scale-out archiving filesystem. It says this is the first GPL archiving file system released.
ScoutFS is a POSIX-compliant clustered filesystem implemented in the Linux kernel, released under the GPLv2 open source license.
The ScoutFS project was started in 2016, to provide for larger POSIX namespaces and faster metadata processing, with the ability to store up to one trillion files in a single namespace by distributing metadata handling across a scale out cluster of commodity compute nodes.
A canned quote from Zach Brown, lead filesystems engineer at Versity, said: “With the amount of metadata growing exponentially, a filesystem that can scale to ultra large file counts and index metadata is very important to the open source storage ecosystem. The ScoutFS architecture keeps things simple while maintaining POSIX compliance, handles small files well, and maximizes performance for bandwidth, all features that are needed with challenging exascale workloads.”
A closer look
Scout FS is a POSIX-compliant, shared-block filesystem that is designed for a large namespace, substantial bandwidth, and is said to handle small files well. It indexes files by users.
It maintains data integrity, is highly-available, and scales out horizontally using commodity hardware. There are parallel reads and writes to archive storage media; parallel within one file or multiple files across multiple hosts
The archive application, Scout AM, is designed to scale as object storage systems scale. It is aware of node resources and spreads work. The application supports dump/restore from VSM 1.x and other Hierarchical Storage Managers (HSMs.)
There is no central MDS (Meta Data System), no scanning and metadata is processed on all nodes.
The metadata is VSM-indexed, with a Metadata Sequence Number (when inode attributes change) and Data Sequence Number (when file contents change).There are also specific extended attributes.
We are told Scout FS has an Accelerated Query Interface (AQI). The filesystem indexes all inode attributes, with no external database being required. It scales with attribute changes and not the inode count. File system scanning is eliminated and there are faster results to queries.
A chart comparing AQI and XFS performance shows this;
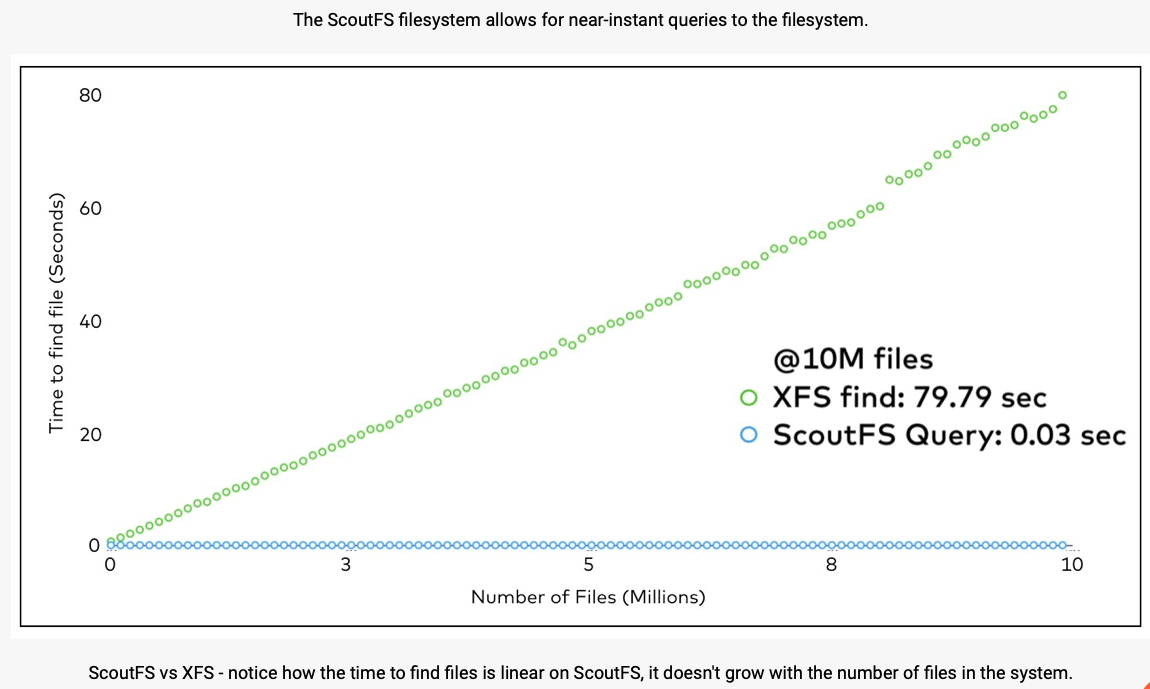
The metadata is stored in a modified Log-Structured Merge (LSM) Tree which is said to be unconstrained by IOPS. An index is stored in the metadata and maintained atomically.
A single IO transaction with multiple operations is used to update the metadata structure, and inodes are organised so the archiver can implement policy quickly. These structures aren’t typically found in other filesystems.
For data integrity the application all the way out to media is protected. Storage devices not blindly trusted with three elements always being checked; identity, location, time.
Versity versus Komprise
We asked Meghan McClelland, Versity’s VP for Products, to compare ScoutFS with Komprise’s file virtualization technology.
She said the big difference between Versity and Komprise is the type and scale of archiving: Komprise is a data mover whereas VSM is an archiving platform.
‘Komprise uses a symlink method to move data that is less frequently accessed by users from one filesystem to a second lower cost storage system without changing the way the files appear in the users directory structure. This is a cool solution to free up valuable space on primary storage systems.
“From what we know, most of their customers are tiering off of filers like NetApp where there is a certain amount of static data sitting around. The big limitation with data movers like Komprise is that they do not relieve pressure on the namespace.
“Each symlink that is left behind on the primary storage still requires an inode in the filesystem so the metatdata collection which is the most congested and least scalable aspect of the primary storage system does not get any relief from the data mover. The data mover companies tend not to discuss this, possibly because they are not yet dealing with larger scale data collections where there may be 500 million to 1 billion files and the namespace is under capacity pressure.
“Versity on the other hand is the tool customers use to build and operate a large archive (5+PB) where both the file contents and the file metadata are moved to a new stand alone location.
“Our ability to scalably manage enormous quantities of metadata (ScoutFS), along with the archival data is the key differentiator. Other things that differentiate VSM from data movers are the following;
- Packaging files into larger archive sets so that large and small files are grouped for optimal throughput performance to tape or object/cloud systems
- Policies allowing admins to automatically direct certain types of data to different locations or to control the number of copies by user, data type, etc.
- Data retention features like WORM
- Data integrity validation including metadata block checksums
- Ability to write to multiple archival resources (tape, object, cloud) from one interface.
“Finally, performance in terms of the amount of data that can be moved is really in a different class. VSM is capable of moving ingesting data at a rate of up to about 22GB/s and writing it out to the archival media at a rate of about 12GB/s with our current product. We natively handle the process of writing to tape at maximum speed whereas the data movers typically rely on an additional hop through a device like “Black Pearl” which limits performance.
“Overall, we like data movers and in fact we have our own tool called Archive Fabric Module (AFM). We give this away free to subscribers but we also act as a target for other data movers and the Versity solution would work very well with Komprise. However, we do not see a lot of overlap in the market. In the past five years, I don’t think we have ever directly bid against them. It’s really a different set of use cases; overflowing NetApp filers, vs. building massive data archives.”
Versity has also produced its Versity Storage Manager for long term storage, and retrieval of massive data stores both on premise and in the cloud. Z





