


CoreWeave’s AI Object Storage service shifts object data around the world at high speed, using Local Object Transport Accelerator (LOTA) technology, with no egress or request/transaction/tiering fees.
It says high-performance AI training relies on large datasets located near GPU compute clusters, like the ones in its GPU server farms. CoreWeave reckons conventional cloud storage isn’t engineered for the level of throughput or flexibility needed, leaving developers constrained by latency, complexity, and cost. Its LOTA tech makes a single dataset instantly accessible, anywhere in the world.

Co-Founder and CTO at CoreWeave Peter Salanki says: “We are rethinking storage from the ground up. We’ve built a system where data is no longer confined by geography or cloud boundaries, giving developers the freedom to innovate without friction or hidden costs. This is a truly game-changing shift in how AI workloads operate.”
Game-changing? Probably yes for CoreWeave customers.
CoreWeave says its AI Object Storage performance scales as AI workloads grow, “and maintains superior throughput across distributed GPU nodes from any region, on any cloud, or on-premises.” It has a multi-cloud networking backbone with private interconnects, direct cloud peering, and 400 Gbps-capable ports to provide this throughput. The throughput is up to 7 GBps per GPU and it can scale to hundreds of thousands of GPUs.
The AI Object Storage service has three automatic, usage-based pricing tiers that “provide more than 75 percent lower storage costs for our existing customers’ typical AI workloads” which makes it “one of the most cost-efficient, developer-friendly storage options in the industry.”
- Hot: Accessed in the last 7 days
- Warm: Accessed in the last 7-30 days
- Cold: Not accessed in 30+ days
Holger Mueller, VP and Principal Analyst at Constellation Research, said; “Leveraging technologies like LOTA caching and InfiniBand networking, CoreWeave AI Object Storage ensures GPUs remain efficiently utilized across distributed environments, a critical capability for scaling next-generation AI workloads.”
LOTA details
CoreWeave’s Local Object Transport Accelerator (LOTA) is an intelligent proxy installed on every GPU Node in a CKS (CoreWeave Kubernetes Service) cluster to accelerate data transfer. LOTA provides a highly efficient, local gateway to CoreWeave AI Object Storage on each node in the cluster for faster data transfer rates and decreased latency.
From the user point of view; “with LOTA, software clients can easily interact with CoreWeave AI Object Storage through a new API endpoint. Clients only need to point their requests to the LOTA endpoint [http://cwlota.com] instead of the primary endpoint [https://cwobject.com], with no other changes required to S3-compatible clients.”
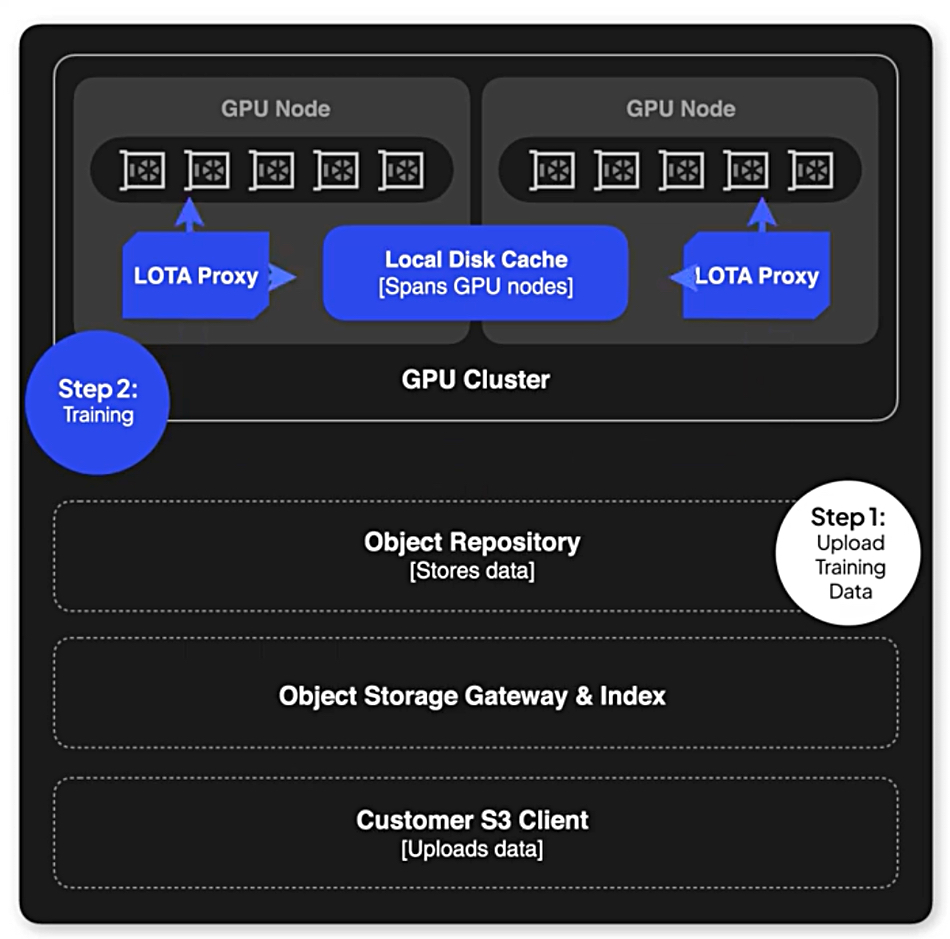
We’re told by CoreWeave that “LOTA proxies all object storage requests to the Object Storage Gateway and storage backend. First, LOTA authenticates each request with the gateway and verifies proper authorization. Then, when possible, LOTA bypasses the gateway and directly accesses the storage backend to fetch objects with the greatest possible throughput. LOTA stores the fetched objects in a distributed cache to significantly boost data transfer rates, especially for repeated data requests.”
When LOTA uses the direct path to bypass the Gateway and access the object directly, data transfer rates improve significantly. By storing the data in a distributed cache, LOTA ensures that frequently accessed objects are readily available for quick retrieval.
LOTA actively caches recently accessed objects on the local disks of GPU Nodes – tier 0 as Hammerspace would say, significantly reducing latency and boosting read speeds for CoreWeave AI Object Storage. The following diagram illustrates the process flow when fetching an object using LOTA;
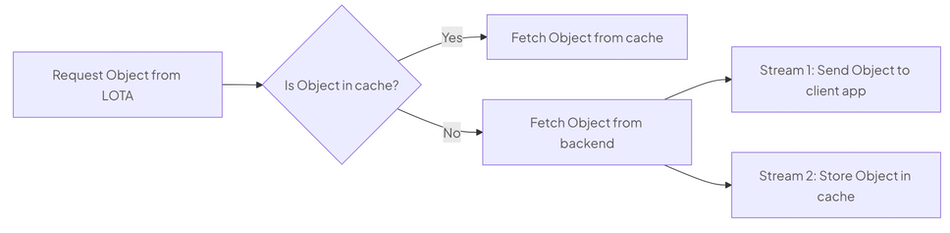
When a request is made to LOTA, it first checks if the object is available in the cache. If the object is found, it’s fetched directly from the cache, ensuring minimal latency.
If the object is not in the cache, LOTA fetches it from the backend storage (whether or not the backend resides in the same Availability Zone as LOTA) and forks it into two pathways:
- Stream 1 sends the object to the client application.
- Stream 2 stores the object in the cache, using local storage on one or more GPU nodes.
This dual-pathway approach—implemented as two concurrent data streams—ensures that future requests for the same data are served quickly from the cache, enhancing overall performance. LOTA distributes the cache across all GPU Nodes in a CKS cluster, ensuring efficient data retrieval and management.
CoreWeave has 28 operational regions spread across the USA, two in the UK, and three in mainland Europe – Norway, Sweden and Spain. Regions are interconnected with high-speed dark fiber. LOTA acceleration will expand to other clouds and on-premises environments in early 2026.
There’s an Object Storage service blog here. See here for more information about LOTA. For a deeper detailed look go here. Basic info on CoreWeave storage can be found here.
CoreWeave recently announced ServerlessRL, the first publicly available, fully managed reinforcement learning capability. And it has a deal with Poolside, a foundation model company, to deliver AI cloud services that support Poolside’s mission to build artificial general intelligence and power the deployment of agents across the enterprise.
Under the agreement, CoreWeave will provide a state-of-the-art cluster of Nvidia GB300 NVL72 systems, including more than 40,000 GPUs. Separately, CoreWeave plans to provide Poolside with its market-leading cloud solutions for Project Horizon, Poolside’s 2GW AI campus in West Texas. As part of the initiative, CoreWeave plans to serve as the anchor tenant and operational partner for the first phase of the project, which comprises 250MW of gross power and includes an option to further expand capacity by an additional 500MW.





