


Liqid can turn Dell servers into on-prem AI model training powerhouses by making up to 30 NVIDIA L40S GPUs available to a single Dell R760 server, it says.
Liqid supplies composable server Matrix software and also hardware using a PCIe fabric and switch to connect x86 processors and memory with enclosures fitted with accelerators, storage and networking gear. The aim is to dynamically configure or compose servers for particular workloads, with calibrated amounts of server component resource, so that there are no unused resources sitting idle and stranded in a fixed configuration server, as can be the case. Once a workload completes then its component resources are returned to the Liqid pool for reuse.

It can also be used to dynamically configure servers with far more accelerator resources than a static configuration can typically support. This is what it is demonstrating at Dell Technologies World 2024 (DTW24) this week in Las Vegas.

Liqid co-founder and chief strategy officer Sumit Puri was quoted in a coming blog as saying: “Efficient deployment of AI applications is critical for our customers. Liqid’s innovative UltraStack configuration, developed in collaboration with Dell Technologies and NVIDIA, packs 30 NVIDIA L40S GPUs behind a single CPU. This allows fewer servers to handle more work, drastically cutting both capital and operational expenses, and significantly boosting AI performance, efficiency, and sustainability.”
In November last year Liqid announced a 16-GPU UltraStack reference architecture for Dell R760xa servers and NVIDIA L40S GPUs. It upgraded this to 20 GPUs in March this year and has now gone further, supporting up to 40 L40S GPUs.
NVIDIA’s L40S GPUs are less powerful generally than its H100 and A100 accelerators, and also its newer Blackwell GB200 and B200 systems, meaning fewer cores, not so much memory and lower bandwidth. Generative AI model training, producing systems such as Llama 2 and GPT-4o, is carried out on massive GPU farms with hundreds if not thousands of GPUs costing many millions of dollars. This puts such training out of reach of all but hyperscaler-class enterprises, such as Meta and the larger public clouds.
Smaller training runs, such as refining a generalised model for particular use cases, can more realistically run on-premises, or rent time at an MSP with a GPU farm, such as CoreWeave. Deciding whether or not to use such an MSP can come down to data sovereignty issues and also to concerns about exposing highly sensitive information outside the corporate IT walls, or the prolonged data transfer time to get it to a cloud GPU farm resource.
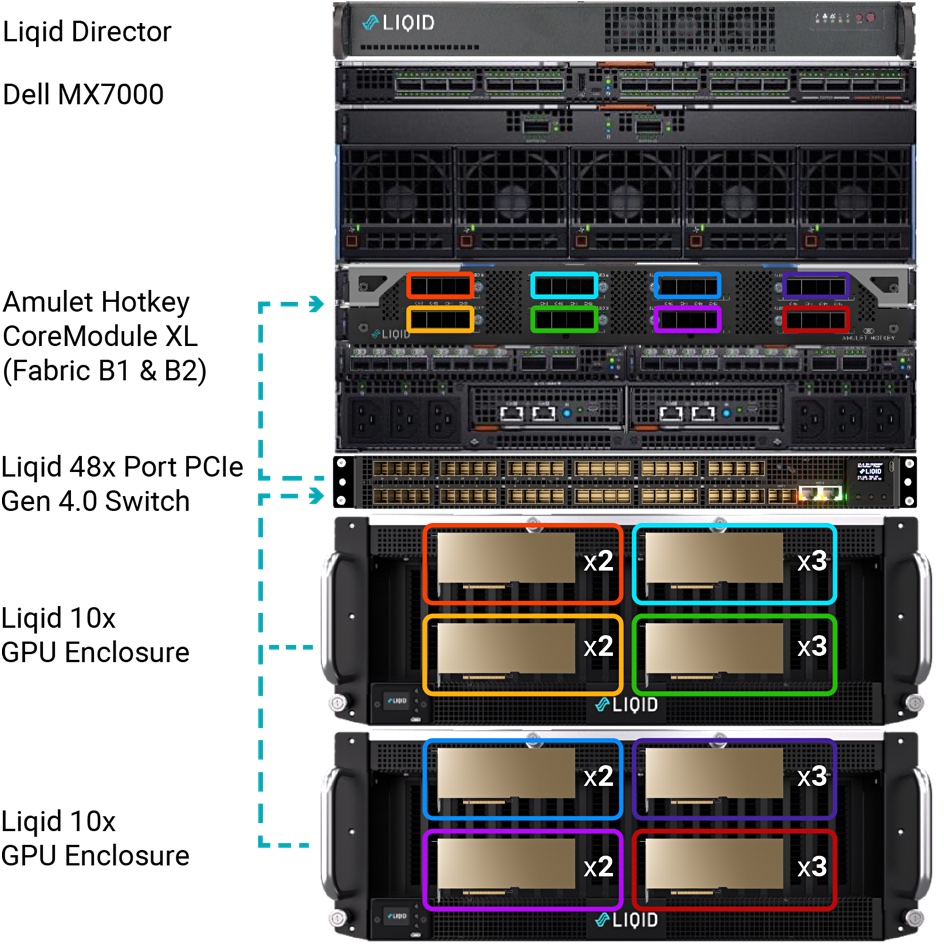
This is where Liqid comes as its UltraStack technology can turn a single Dell R760 AI server into a mini BasePod to carry out model fine tuning using proprietary data. Its allied SmartStack technology can take the same GPU resource and provide it to many clients in dynamically composed slices.
The Liqid blog claims:’The latest 30-way Liqid UltraStack offerings builds upon the 10- and 20-way solutions released in late 2024 and delivers a 2x improvement in operations per second and 50 percent lower TCO than a comparable GPU density delivered by four 8-GPU servers, redefining the limits of high-density GPU systems.”
Liqid has qualified Dell’s PowerEdge modular infrastructure systems, meaning the PowerEdge C-Series – C6620, C6625, and C6615 – with its SmartStack offering. This enables the attachment of up to 20 GPUs to a single modular server node. SmartStack also supports the MX7000 and the attachment of up to 20 GPUs per MX760c, MX750c, and MX740c compute sleds (blades).
Our understanding is that Liqid can support GPUs and other accelerators from suppliers such as AMD and Intel. It is also aware of the possibility of marketing its SmartStack and UltraStack technologies to MSPs that wish to supply GPUs for rent.





