


Korean startup Panmnesia says it has a way of running recommendation models 5x faster by feeding data from external memory pools to GPUs via CXL caching rather than host CPU-controlled memory transfers.
Its TrainingCXL technology was developed by computing researchers at the Korea Advanced Institute of Science & Technology (KAIST), Daejeon. Panmnesia, which means “remember everything,” was started to commercialize it.
Panmnesia’s CEO is KAIST associate professor Myung-Soo Jeong, and he said in a Seoul Finance interview: “ChatGPT, which has recently become an issue, requires more data as technology develops, and more memory to store it.” High-bandwidth memory (HBM) will not solve this issue: “Even if memory performance is increased through HBM, connection technology that can gather each memory module in one [virtual] place is essential to increase storage capacity.”
What Panmnesia has developed is DirectCXL, a hardware and software way of implementing CXL memory pooling and switching technology specifically for recommendation engines but benefiting other large-scale machine learning applications.

Recommendation engine models are machine learning processes used by Facebook, Amazon, YouTube and ecommerce sites to suggest products to users based on what they are currently buying or renting. Computer eXpress Link (CXL) is technology for interconnecting devices with memory across a PCIe gen 5 or gen 6 bus-based system so that they can share data in physically separate but coherent memory areas. Panmnesia accelerates data access in distributed CXL memory pools by using the CXL caching protocol, cxl.cache, and reduces model run time by doing some processing in its CXL memory controllers.
The technology’s background is is described in two complex academic IEEE papers. “Failure Tolerant Training With Persistent Memory Disaggregation Over CXL” uses Optane PMEM for the external memory. “Memory Pooling with CXL,” meanwhile, which is behind a paywall, uses DRAM.
To understand what’s going on – how Panmnesia achieves its >5x speed up – we need to visit the basics of the hardware scheme and its CXL components, and get to grips with a few recommendation engine technology concepts.
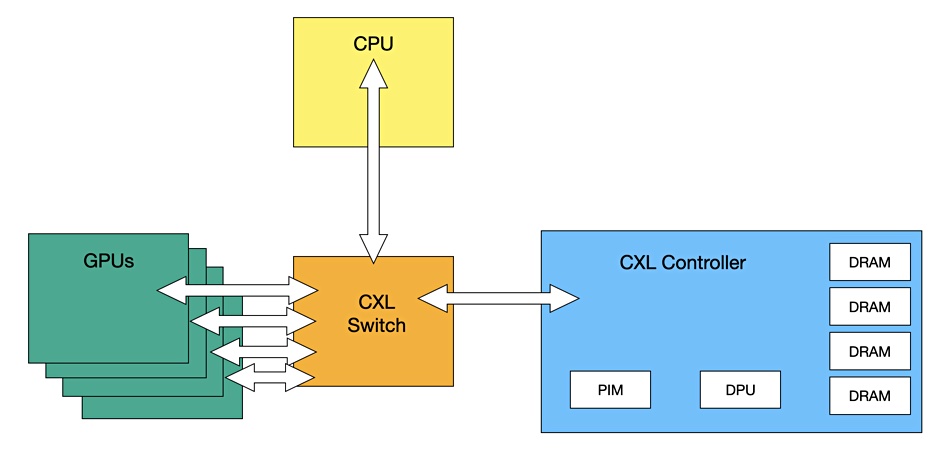
Hardware and CXL
Panmnesia’s technology has a CXL v2 switch and CXL Memory controller providing access to shared external CXL memory both to a CPU and to GPUs, each with their own local memory capacity. This shared coherent memory pool is referred to as a Host Physical Address (HPE) and is larger than the individual memories of the GPUs and the CPU, thus enabling the data for large recommendation models to be stored in memory instead of being fetched piecemeal from much slower SSD storage. The controller also has a PIM (Processing-in-Memory) capability plus an additional near-data processor, oddly called a DPU. These speed recommendation engines work by preprocessing certain kinds of data, reducing it in size and processing complexity before sending it to the GPUs.
The recommendation engine model relies on data items called embedded vectors, with vectors being a set of numeric values in arbitrary dimensions – tens, hundreds or even more of them – that describe a complex data item such as a word, phrase, paragraph, object or image or video. Vector databases are used in AI and ML applications such as semantic search, chatbots, cybersecurity threat detection, product search and recommendations.
A machine learning model takes an input vector, describing an item, and looks for similar items in a database, making parallel and repetitive calculations to arrive at its decision. Crudely speaking, the larger the database and the more comprehensive the vectors, the likelier you will be recommended a follow-on Bourne movie while checking out the first one rather than Good Will Hunting.
Training recommendation engines can take days, which is why a 5x speedup is desirable. The embedded vectors are loaded into the CXL controller’s DRAM. They are then, using the CXL.cache protocol, made available to the GPUs with the model being run and intermediate values fed back to the CXL controller’s memory the same way. Using the CXL.cache protocol means that the host CPU does not have to move the data from one HBM memory area to another, saving time.
Having the PIM and DPU elements in the controller preprocess the embedded vectors, reducing them in size before sending them out to the GPUs for the next training cycle, means that work can be done in parallel with the GPUs which, of course, are also operating in parallel. It all goes to save time and avoid buying more GPUs to get more GPU memory.
As enterprises adopt ChatGPT-style chatbots to operate on their own private data sets, they will need training and this represents a large emerging market for Panmnesia. A TrainingCXL video describes the technology in its PMEM incarnation.
Panmnesia’s founders have patented some of their technology, with applications for more patents under way. All in all the technology looks worth following as Panmnesia’s academic founders establish their company and set up business processes and technology documentation. Check out its website – it has lots of content.




