


Israeli startup Treeverse is developing dataset copy management and version control for data pipeline builders with its open-source Lakefs product.
Analytics and AI/ML data supply pipelines depend upon consistent, repeatable and reliable delivery of clean data sets extracted from source data lakes. Such pipelines are equivalent to software programs and they take effort and time to develop and test. The testing effort requires datasets on which the pipeline operate and these are mostly copies of a source dataset. If the source dataset has a snapshot, copies made then can be used to create virtual copies, timestamped sets of pointers to a source dataset that can be used for pipeline development.
Lakefs says it brings such version control to datasets.
Co-founder and CEO Einat Orr told an IT Press Tour audience in Tel Aviv that: “LakeFS is an open source project that provides data engineers with versioning and branching capabilities on their data lakes, through a Git-like version control interface.”
This enables zero copy dev/test isolated environments, continuous quality validation, atomic rollback on bad data, reproducibility, and more, the company said.
Treeverse is creating software tools to aid engineering best practices for data practitioners. Orr and co-founder CTO Oz Katz worked at SimilarWeb wherev they told us a small bug caused 1 PB of data to be lost. The recovery of thousands of tables took three weeks. It would have been much simpler to do that if the datasets involved had version control, said Orr. That realization spurred the two to start up their business and create the Lakefs software product.
The same problem exists with data warehouses and their structured data, Orr said. But it was relatively minor and, with data lakes, unstructured data joined the structured data and dataset complexity and scale grew and grew.
The Lakefs concept starts with a main dataset and snapshot (virtual) copies, branches, made from it. These branches proliferate and are managed as if in a tree, with the Lakefs software traversing the tree. The source data is stored in object buckets – S3 in AWS, Azure Blob, GCP, and MinIO – with Lakefs creating deduplicated metadata, pointers to the source data, and managing and operating on that.
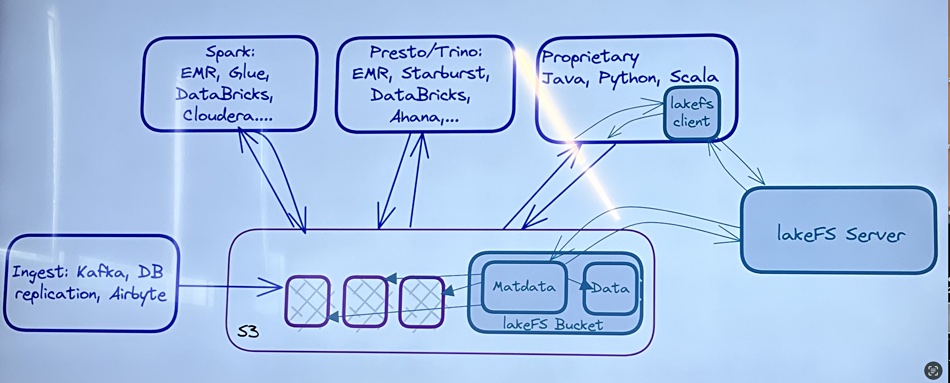
Accessing systems used by pipeline developers have an Lakefs client which contacts a Lakefs server. This provides access to dataset metadata. When a virtual copy is made of a source data set this becomes data (a set of pointers) as far as Lakefs is concerned and both this and the source dataset metadata is stored in an S3 bucket.
To create this technology, Orr said: “Lakefs bring Git-like operations to data with version control. We took the language of Git and implemented a new system of primitives that run over data.”
It creates snapshots as a soft copy of the data. These are not like storage snapshots that are used for data recovery. It happens on a different layer. A dataset can include hundreds of thousands of tables. If a dataset version needs reversing to a prior version, then Lakefs can do it in a single atomic operation. Previously engineers would do it manually, which is time-consuming and error-prone.
Orr said Dremio, an analytics engine over data lakes, is the closest competition to Lakefs with its Iceberg. This has limited functionality, she added, but the same use cases and is extremely specific to Iceberg’s open table format. Lakefs doesn’t care what format the data is and takes an infrastructure or general approach to data version control.
The first deliverable product was released in August 2020, Orr said, eight months later the company was founded, and then a year was spent refining and developing the product. The first supported Lakefs version appeared in July 2022.

There are integrations with other products in a dataset operations ecosystem. The product can provide dataset version control across multi-stage data pipelines, eg: AWS S3 – to Snowflake – to Postgres. It can also provide an audit trail for datasets with compliance regulation fit.
There are more than 4,000 members in the Lakefs open source community and many familiar customer names are nestled in the user list, which now includes Ford and Disney.
Lakefs is available on-premises or as a managed cloud service (SaaS). The supported on-premises version and the SaaS version are priced from $2,500/month.
Lakefs has raised $23 million across a seed round and a venture round led by Dell Technology Ventures with Norwest Capital and Zeev Ventures. There are 25 employees, 15 in Tel Aviv and the remainder in San Francisco, New York and the UK. The company was actually incorporated in the US.
The software is available in the In AWS marketplace and will soon be available in Cloudera’s marketplace. It’s trying to get into Snowflake’s marketplace, Katz said.
Working on increasing its data granularity and added delta lake support for Databricks, it wants to add support for more datasets, such as Snowflake.
Comment
We think Snowflake is a good prospect. It has a dataset marketplace so users get to manage many, many more datasets. This makes the data set management prospects for Lakefs in Snowflake attractive. Ditto Databricks and so on. In general the surge in AI/ML use will increase dataset numbers and usage exponentially and is another good prospect for Lakefs.
There is a DataOps technology area in which Delphix operates. Dataset management can be seen as a subsection of this. But there are no links between Lakefs and Delphix. Other players in the data versioning landscape are in the end-to-end MLOPs area (HPE-acquired Pachyderm, iterative and DAGsHub), data-centric AI (Galileo, Lightly, Graviti and others), and databases (splitgraph, Snowflake and DOLTHUB).
Lakefs told us it is the only supplier developing and selling a general infrastructure oriented product.





