


Equipping high IO applications with internal storage engine code makes their data ingest, search and read faster than just leaving these operations to external SAN, filer or object storage controllers.
We’re thinking of Airbnb, LinkedIn, Meta, MinIO and WhatsApp here and the realization above was sparked by reading a LinkedIn article written by Bamiyan Gobets, CRO of Speedb. B&F described this startup in April last year and now Gobets has filled in some technical background. Gobets’s career history includes time spent as a Unix support engineer for Sun Microsoystems, a support engineer at Auspex and working for NetApp in a variety of engineer roles. He has a solid support background.

Gobets says it’s all about IO for “creating, reading, updating, and deleting (CRUD) data on physical disk and external disk arrays. When done right, this creates dramatic efficiency gains for the application by eliminating read, write and space amplification from compactions on an LSM-Tree, or inserts on writes for a B-Tree.”
So what are LSM-trees and B-trees?
Imagine an application has a high IO rate and this might be biased towards writes or for reads. An LSM-tree is a data structure optimized for writes while a B-tree is better structured for reads. The data here is typically an item with a value, a key:value pair such as [pen-2] or [phone-56]. “Pen” and “phone” are keys and “2” and “56” are values. The need is, first, to store them on persistent media, disk or SSD after they arrive in the application’s memory and, secondly, to find and read them quickly if they are subsequently needed.
A LinkedIn key:value pair could be [Mellor – CRO job role details], and this could be ingested when I enter a new role in my LinkedIn entry, and read when someone looks at my entry.
A problem is that data arrives in an application’s memory in random order, needs to be written to disk sequentially to optimize disk storage, and indexed so it can be found quickly. An application could leave all this to a SAN or filer, relying on that external device’s storage controllers and software to do the job. But that device can be shared with other applications and so not optimized for any particular one, slowing down an app’s IO.
If the app has an in-built or embedded storage engine, it can present better-organized data to the array, making its storage and subsequent retrieval more efficient and faster.
B-Tree
One way of writing data is just to append it to existing data. Then you search for it by reading each piece of data, checking if it’s the right one, and reading the next item if it is not. This can, however, take a very long time if your database or file has a million entries. The longer the file, the worse the average search and read time. We need to index the file or database so we can find entries faster.
A binary search tree and a B-Tree both store index or key:values for data items. A binary tree has a starting point or root, with a few layers of nodes. Each layer is laid out from left to right and a node has a key:value that is greater than nodes to the left and smaller than nodes to the right. To find a particular key, you progress down through the layers in the tree util you arrive at the node with the desired value. The deeper the tree and the more nodes, the longer this takes.
A B-Tree fixes this problem. It has a starting point or root with a small number of node layers called leaves and children. We’ve drawn a simplified diagram to show this. Note that there are different definitions of what is a leaf node and what is not. We have kept things simple and may be oversimplifying. Bear with us, the point is to contrast this with the LSM-Tree.
A node can hold one or more keys, up to a limit, which are sorted. The numbers in each node in our diagram are range limits. The left-most child node, for example, has a range of keys between 5 and 15. If we have a leaf node with a range of 20 to 150 then we know all key:values below 20 will be in its left-most child, key:values between 20 and 150 will be in the middle child, and keys valued at more than 150, but less than 500, will be in in its rightmost child.
As you add more data, a B-tree gets more index values which have to be added. This can lead to more leaf nodes and child nodes, with nodes being split in two, and reorganization going on in the background.
The B-tree has far fewer layers than a binary tree which reduces the number of disk access needed to search it. This makes a B-tree scheme good for read-intensive workloads. However, Gobets says: “In general, considering IO ingestion is most challenging from a physical perspective, LSM-Tree has been most widely adopted, and also has the most theoretical potential to optimize reads through innovation, therefore ideal for modern, large scale workloads.”
LSM-Tree
The Log-Structured Merge Tree concept has ordered key:value pairs which are held in two or more places such as an in-memory structure and a storage structure. We can envisage three such structures: (1) an in-memory container to hold incoming data requests as a hash table or K:V pair table, (2) when full the in-memory container contents are written to one or more sorted and indexed in-memory delta container, freeing up the in-memory container, (3) base storage structure into which the delta container contents are batch written or merged in a way that is consistent with the disk structure.
The merging or compaction is a background operation. Once deltas are merged into the base they are deleted. A search is then a three-step process, looking into each data structure in turn until the item is found.
Gobets says that the code for an LSM-Tree does not have to be written from scratch. Developers can link to libraries of such code. There are three popular open source libraries for this – LevelDB, RocksDB and Speedb. Speedb is a rewritten RocksDB implementation that, the company claims, is significantly faster than RocksDB.
He says thousands of enterprise apps use LSM-Tree-based storage engines and lists some prominent LSM-Tree app users:
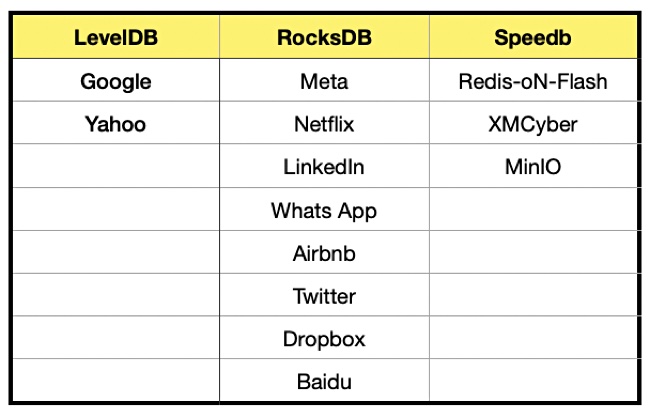
He says: “These embedded storage engines offer the highest-performance data storage capabilities, enabling massive scale and stability under pressure, which is critical to the success of these companies and our experiences with their products.
“This approach is the most efficient for massive ingest of data because it allows new data to be quickly written from sorted arrays in memory, perfectly aligning aggregated bytes (in memory) to fill complete blocks (on disk), while still allowing for efficient retrieval of new data from memory, and old data from disk.”
Of course Gobets is a CRO and has software and support to sell. Even so, his article is educational and informative about the need for B-Trees and LSM-Trees.





