


A Blocks & Files report, based on Register and B&F reader responses to an online questionnaire, shows that automated data management is a long way off.
The report, Data Management is Still Manual Labor for Most Register Readers, looked at three general topics: storage tiers and data placement; on-premises and public cloud data movement; and use of data warehouses and lakes. The responses came in from more than 750 IT professionals – some 375 in Europe, slightly less than 200 in North America and others in Asia and Latin America.
We recorded responses to various questions added to the bottom of articles and this report looks at responses to those questions focused on data management. They provide a series of snapshot views and we highight one area here.
One group of questions looked at what storage tiers were in use, and the results confirmed that SSD take-up has been remarkably popular:
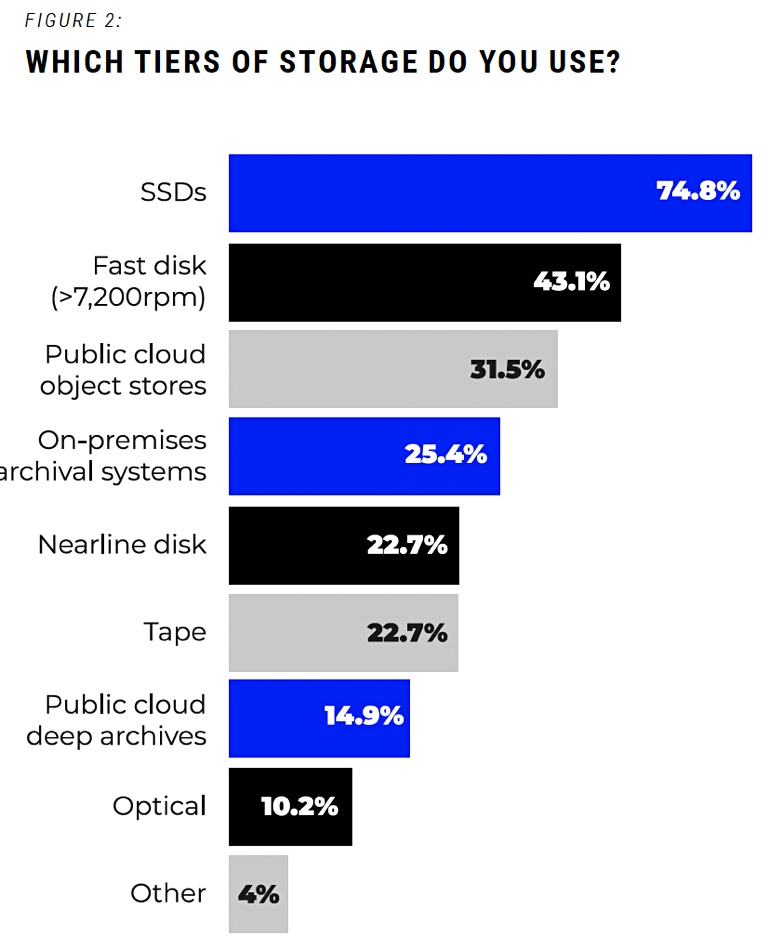
A surprising number of responders said fast (2.5-inch 10Krpm) disks were in use – 43.1 percent – more so than the 22.7 percent saying nearline disks (3.5-inch, 7,200rpm) are deployed in their organizations. Possibly that’s due to hyperscalers buying the largest number of nearline drives.
It’s clear that several tiers of storage exist and we wanted to see how data was placed on the tiers. A big pitch of data management suppliers is that data should be placed in the right tier to get the best balance between performance and cost for the data’s access needs. This activity should reduce data storage costs by moving data off expensive and high-performance tiers. More than 60 percent of responders said they did not use data management software to do this; data placement wasn’t automated.
That surprised us. Perhaps older data was deleted so there wasn’t so much data placement pressure? Yes – slightly more than 63 percent deleted data, and did so manually (60.6 percent) with half using both data’s age and access level as the criteria for deletion.
Other findings concern data and app movement between the on-premises and public cloud environments, looking at the effect of egress charges, and also aspects of data warehouse and data lake use.
Take a look at them – the six-page report can be accessed in PDF form here.





