


Imply has added a Polaris database service and faster query engine to its open-source Druid core.
Apache Druid is a database providing real-time query answers from vast sets of streaming and historical data. Imply is a startup founded by Druid’s code originators – CEO Fangjin Yang, chief experience officer Vadim Ogievetsky, and CTO Gian Merlino – and it is announcing the first delivery milestone of its 12-month Project Shapeshift to develop a hardware-abstracting, auto-scaling control plane and SaaS service for Druid.
Yang said in a statement: “Today, we are at an inflection point with the adoption of Apache Druid, as every organization now needs to build modern analytics applications. This is why it’s now time to take Druid to the next level. Project Shapeshift is all about making things easier for developers, so they can drive the analytics evolution inside their companies.”
The Shapeshift project is intended to simplify the end-to-end developer experience and extend the Druid architecture to power more analytics use cases for applications from a single database.
Polaris is a cloud-native database service based on Druid and built on the Confluent push-based event-streaming cloud, which runs on AWS. This can support an ingest rate of up to 10 million events per second and means users no longer have to build a streaming ingest engine of their own.
Imply says Polaris does more than cloudifying Druid as it is a fully managed database service with automated configuration, optimisation through performance monitoring, streaming ingest from Confluent, and a visualization engine all accessed through a single UI.
Imply chief product officer Jad Naous said the Polaris cloud service “deploys instantly, scales effortlessly, and doesn’t requires any Druid expertise, enabling any developer to build modern analytics applications.” It doesn’t require any infrastructure management by its users unlike raw Druid.
Query engine
This open-source multi-stage query engine breaks a query into stages, which are executed in parallel to speed up the querying process. The engine delivers sub-second response on queries to PB of data, and hundreds to more than a hundred thousand queries can be run a second.
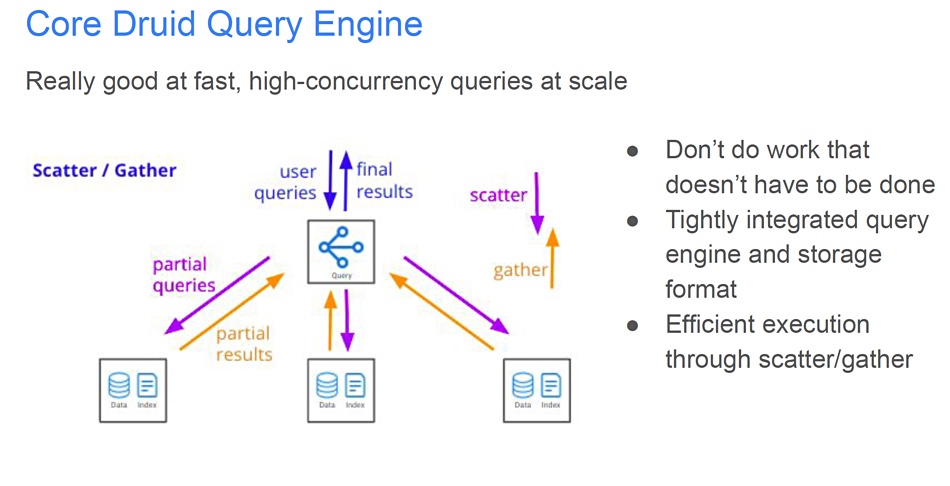
The query engine is accessed with SQL commands and enables Druid reporting, both simple and complex with long-running and heavyweight queries. It also enables alerting through checking a large number of streaming and/or historical entities with complex conditions.
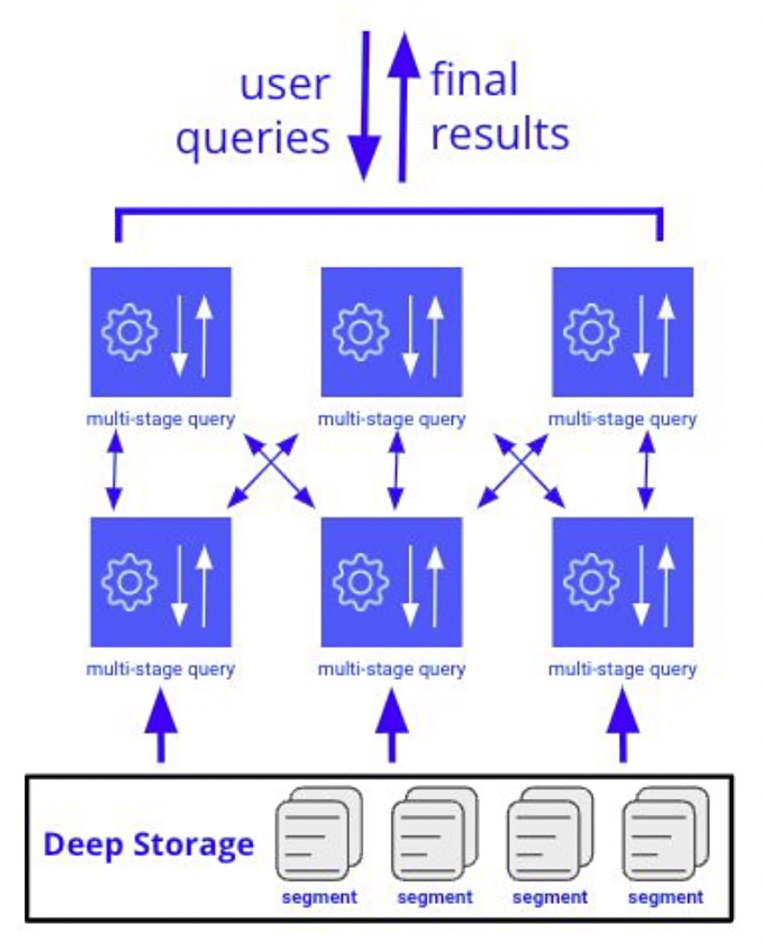
It enables simplified data ingestion from object stores, including HDFS, Amazon S3, Azure Blob and Google GCS, with in-database transformation.
Imply claims that there’s no other database that has the breadth of Druid, its interactivity at scale, concurrency, real-time data, and now ingestion and query flexibility. Users no longer need to be Druid experts and developers can do more.
Comment
Imply believes that business analytics use is going to become widespread and needs interactive query access to both historical and real-time data logging millions of events. A scale-out multi-stage query engine is a necessity as is a single logical database and enterprise ease-of-use features so that querying users don’t have to be infrastructure managers as well.
Ocient and Firebolt are building products and services applicable to this same use case, which all three say goes far beyond what Snowflake and its companions can achieve.
The multi-stage query engine is available in private preview and will be included in Polaris, which is generally available. Email contact@imply.io to request access to the preview.





