


Komprise, the SaaS-based data management lifecycle company, claims it is not like Hammerspace. Unlike Hammerspace, it is not building a metadata-based control plane for a global collection of files that is in the data path – yet it does know about all the files in such a collection because it indexes them. So what is the difference between its Global Data Index and Hammerspace’s Global Data Environment?
This was explored in an IT Press Tour briefing in Silicon Valley. Let’s take it as read that organisations are facing a steadily rising torrent of file and object data, what is called unstructured data, and that keeping it all on filers is not a good idea. They are designed to provide fast read and write access to the files they store and becoming more flash-based than disk drive-based. That’s good for speed but bad for cost. Keeping 100 to 200TB of data on an all-flash filer is affordable whereas keeping petabytes is generally not.
We need a way to identify files that are not being used much, but need to be retained, and move them to cheaper storage. We can ask the customer to do this identification, but the task rapidly becomes impossible. It’s doable with 100 files, 200 files, 300 files but is becoming a growing burden with 1,000, 2,000 … 5,000 files and effectively impossible as we move past 10,000 files to 100,000 files and on to a million files and then, in more and more organisations 10 and 100 million files and even beyond that.
The task has to be automated. The only way to do that is to know what files exist in the first place and where they are. Once we know that we can apply policies to them – such as “move all files which have not been accessed for six months to object storage in the public cloud.”
This is the first thing Komprise’s software sets out to do when it is deployed. It discovers the filers and object stores in an organisation’s IT infrastructure, both on-premises and in the cloud, and indexes their contents – assimilates them in a sense – and builds a global index in the AWS public cloud. It finds and copies all the metadata for an organisation’s files and objects, across all its disparate and heterogeneous systems, and indexes the files and objects using said metadata: item name, address, owner, creation date, type, size, last access date, and so forth.
One Komprise customer has an index of over one hundred billion files. There is no way such a vast population of files could be managed manually.
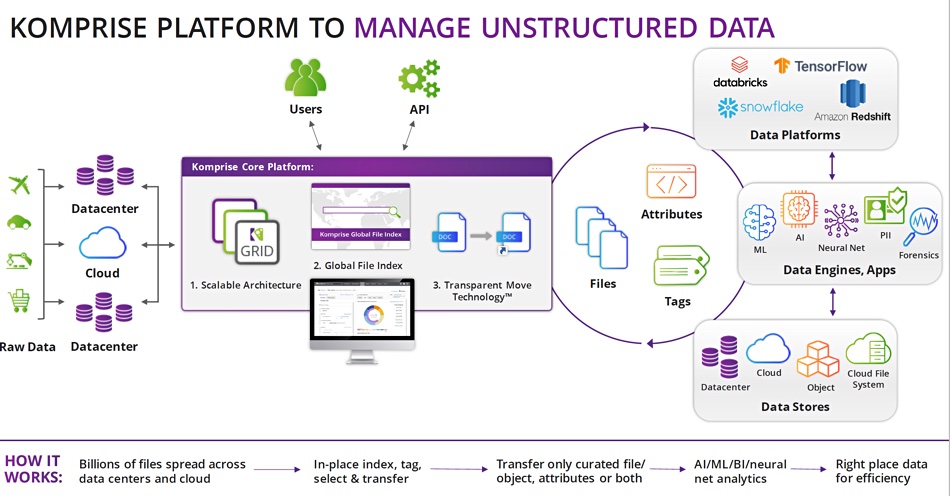
Once that index exists then customers can set policies to define which files should be moved to lower cost storage. This is a very flexible activity. There is no need to have a hard and fast hot/cold data boundary. We start by saying all data on filers, unless otherwise specified, is hot. Then a policy can be set to say all customer orders, for example, in transaction systems must be move to Azure Blob or S3 object storage if they are more than three months old and haven’t been accessed for eight weeks.
Another policy can say that accounting records for a quarter can be moved to long-term and cheaper storage six months after they were last accessed. Yet another might say that all files of type .jpg in the marketing department should migrated to the Google Cloud platform once they are 16 weeks old. The policy setting is infinitely flexible. If there is a metadata item attached to files then it can be used, singly or in combination with other items, to filter files, create a subset, and move files in the subset to colder storage, and that files in Europe must be moved to cold storage in Europe to comply with data sovereignty rules. Workflows can be set up to do this.
Two things come to mind here. One is that the global index must be kept up to date so that, as files in the filers age, are accessed or not, and get deleted, these facts are known and the index updated accordingly.
The other thing is that once a file is moved, it is in a different place and users and applications that may wish to access the moved file can find it. One way for them to do that would be to use the global index, because it must, of necessity, know where all the files are. This, broadly speaking, is the approach taken by Hammerspace, which of course, does much more than move files to cold storage.
Komprise has taken the decision that this is the wrong idea. It replaces the file’s address, before it was moved, with a dynamic link, which points to the new location. As far as users and applications are concerned the file is in its original location and their way of accessing it need not change. This is called Transparent Move Technology.
We can see that Komprise is in the control plane, so to speak, for files its software has moved, but not for files which it has not moved – the so-called hot data.
Deep analytics
Komprise can do more. The index can be queried to show how much capacity is taken up by files of particular classes and a graphical display created to show this. How many files are stored on Qumulo filers? What age are they? How many files have been accessed in the last day, week, month, year and so on. Komprise says this is like a search plane as opposed to a control or data plane.
Its software can also be used to add tags to files, to extend the metadata. Then you can answer questions such as “which image files contain the company logo or personal identity information (PII)” and do things with them. You can set up workflows to have public cloud services, such as AWS Lambda functions, act on subsets of data. Or delete emails by ex-employees that have not been read in 3 years. Such activities are called Deep Analytics Actions. There is API access to these actions and Python scripts can be used to connect data services.
A UK Police Department Digital Forensics unit is using Komprise Deep Analytics to locate and copy files during investigations, meanwhile keeping them accessible on lower-cost cold storage.
Komprise’s global index does not have an intrinsic hot/cold data boundary. It knows about file age and file access history but it doesn’t do anything with that information, apart from find it and display it. It is not a data mover. That is the function of Komprise’s data management services software, and it is only kicked into action when users set policies and have them applied.
The two main benefits of Komprise’s software are to save cost by transparently moving less-accessed files to cheaper storage, with 60–75 per cent cost savings possible, and to enable a much better way to find and then process information needles in the giant file and object haystacks that litter an organisation’s global, multi-silo IT infrastructure.




