


Druva has devised a way of automatically slotting backup data into the appropriate AWS storage layer, a service that it claims, reduces total cost of ownership by up to 50 per cent.
Warm data can be saved in AWS S3, with less often referenced or cool data sent from there to Glacier and rarely-accessed or cold data pushed across to Glacier Deep Archive.
Phil Goodwin, director of research, IDC, gave a warm quote for the Druva launch release that sums up the Druva pitch nicely: “IDC estimates approximately 60% of corporate data is ‘cold,’ about 30% ‘warm’ and 10% ‘hot’. Organisations have typically faced a tradeoff between the cost of storing ever increasing amounts of data and the speed at which they can access the data.
“Druva’s collaboration with AWS will allow organisations to tier data in order to optimise both cost and speed of access. Customers can now choose higher speed for the portion of data that needs it and opt for lower costs for the rest of the data that does not.”
Single pane of glass
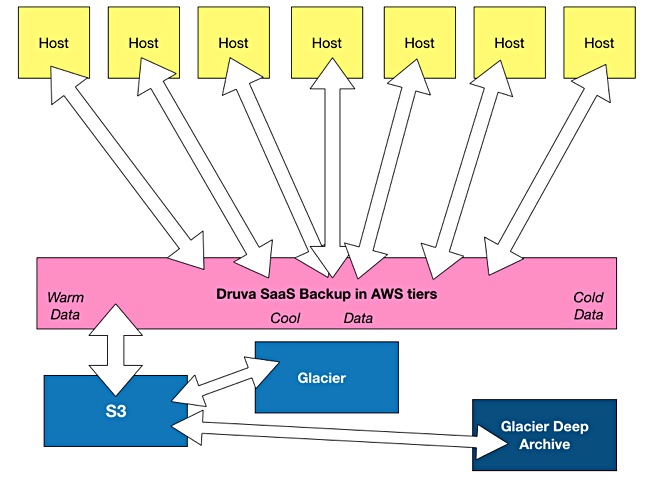
The tiering can be performed by Druva’s software, using machine learning and policies or it can be managed explicitly by customers, using a management dashboard. Policies are also set through this dashboard.
Another quote, this time from Mike Palmer, Druva’s chief product officer: “The ability to see multiple tiers of data in a single pane of glass increases control for governance and compliance and eventually analytics.”
Druva claims it is the only SaaS data protection offering built completely on AWS, and as such is cloud-native.
Blocks & Files expects Druva to make moves towards Microsoft’s Azure and in due course, Google Cloud Platform.
No word yet on availability and pricing for the AWS tiering service. However, Druva today confirmd general availability of its Disaster Recovery-as-a-Service (DRaaS), announced in March 2019.





